In the previous post, I used a C++ CUDA example to look at memory coalescing and how memory access patterns affect GPU performance.
This time, I wanted to look at a similar performance problem from Python.
I usually write CUDA code in C++, but recently I have been spending more time with Python, especially PyTorch and Numba.
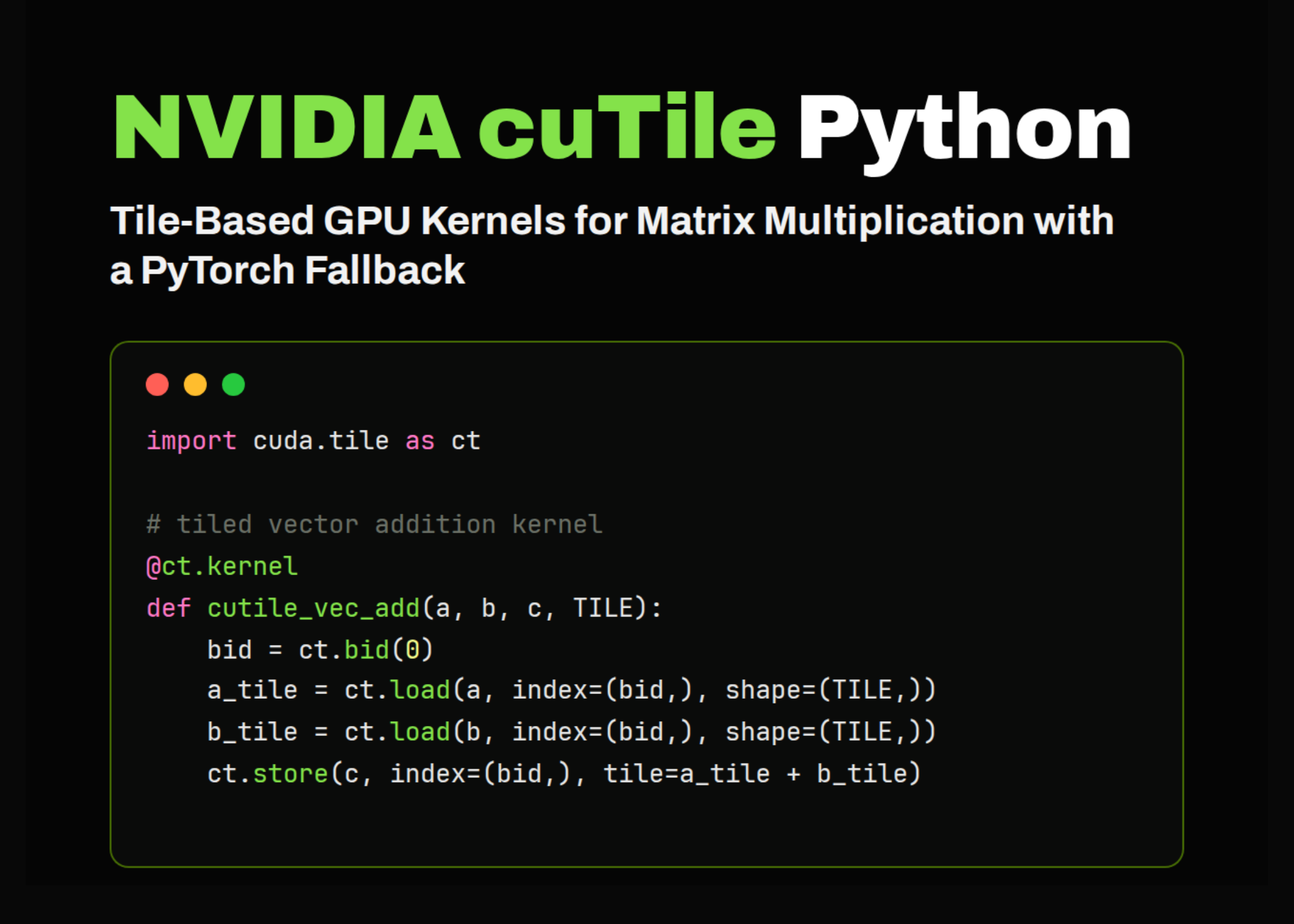
Numba is interesting because it lets you write a real GPU kernel directly in Python. You can decorate a function with @cuda.jit, launch it with kernel[grid, block](...), and Numba compiles it down to GPU machine code that runs on the actual hardware.
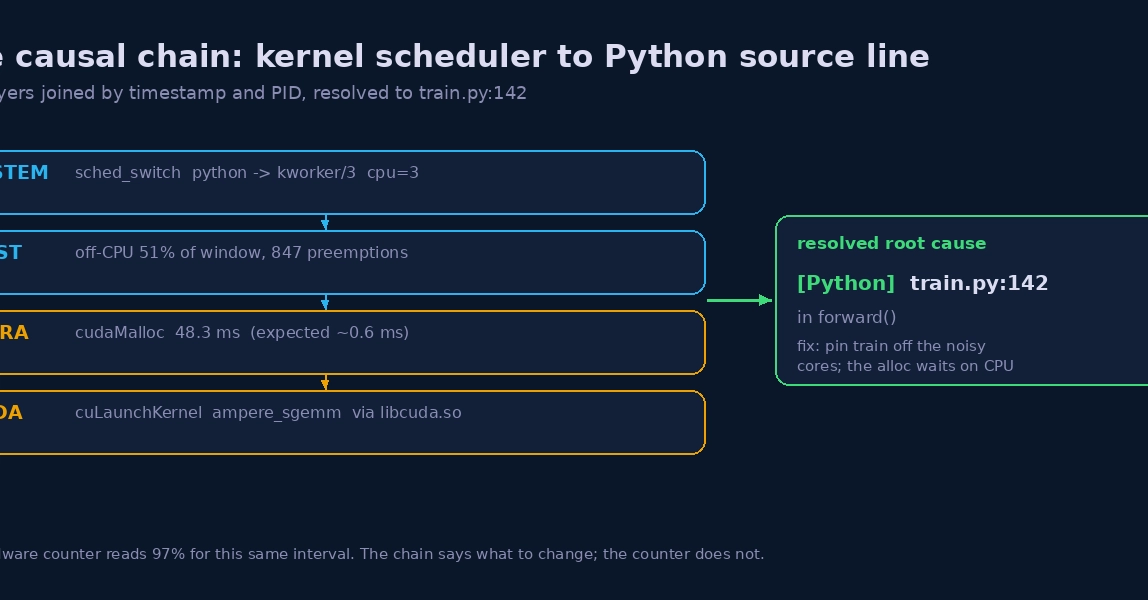
The good news is that GPUFlight can profile Python GPU programs as well.