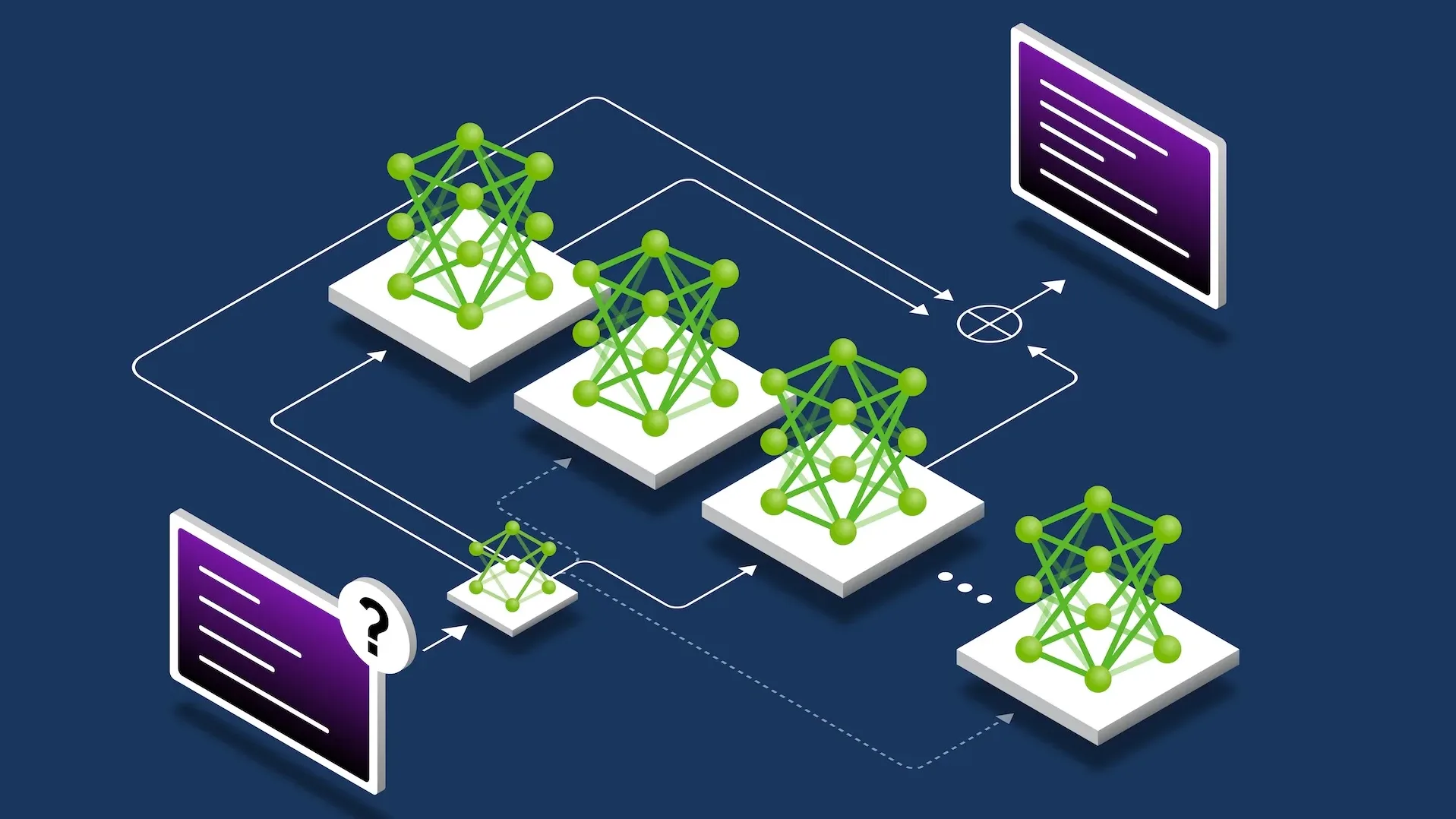
NVIDIA CompileIQ tackles one of the hardest problems in performance engineering: finding the compiler options that unlock the best performance for a specific workload.
Consider a team that has spent weeks optimizing an LLM inference pipeline on GPUs, tuning batch sizes, quantizing to FP8, adopting flash attention, fusing every kernel they can. The profiler says there’s nothing left to squeeze.
But what if you could turn the compiler itself into a tunable parameter? Now you can. The release of NVIDIA CUDA 13.3 includes CompileIQ, an AI-powered compiler auto-tuning framework that uses evolutionary and genetic algorithms to optimize NVIDIA general purpose GPU compilers for individual workloads.
NVIDIA GPU compilers apply the same default heuristics (register allocation strategies, instruction scheduling decisions, loop unrolling thresholds, etc.) to every kernel they compile. These heuristics are engineered to produce good results across a vast range of workloads. But “good across the board” and “optimal for your workload” are two very different things.
The competitive landscape in AI infrastructure has made this gap impossible to ignore. Teams building custom CUDA, Triton, and Helion kernels are striving for every percentage point of throughput. Until now, there hasn’t been a way to fine-tune code generation for a specific workload.