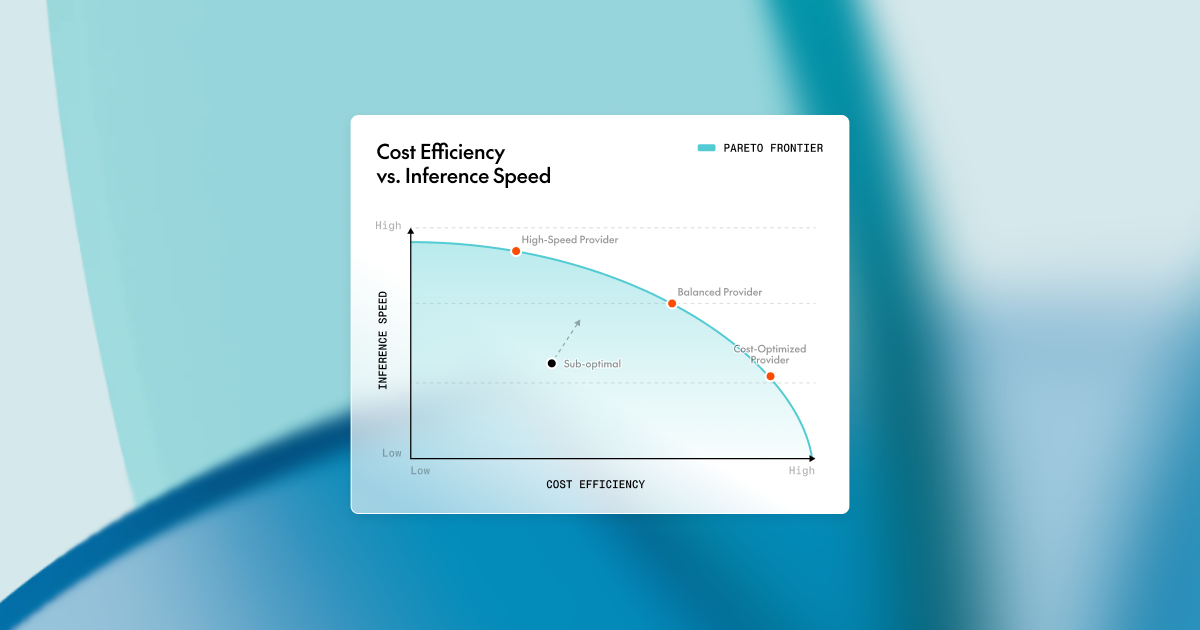
Organizations deploying LLMs are challenged by inference workloads with different resource requirements. A small embedding model might use only a few gigabytes of GPU memory, while a 70B+ parameter LLM could require multiple GPUs. This diversity often leads to low average GPU utilization, high compute costs, and unpredictable latency.
The problem isn’t just about packing more workloads onto GPUs but about scheduling them intelligently. Without orchestration that understands inference workload patterns, organizations face a choice between overprovisioning (wasting resources) and underprovisioning (degrading performance).
This blog post covers:
The inference utilization problem: Why traditional scheduling underutilizes GPU resources.
How NVIDIA NIM delivers production inference: The role of containerized microservices in standardizing model deployment.