Recent
Inference Performance
Mar 23, 2026
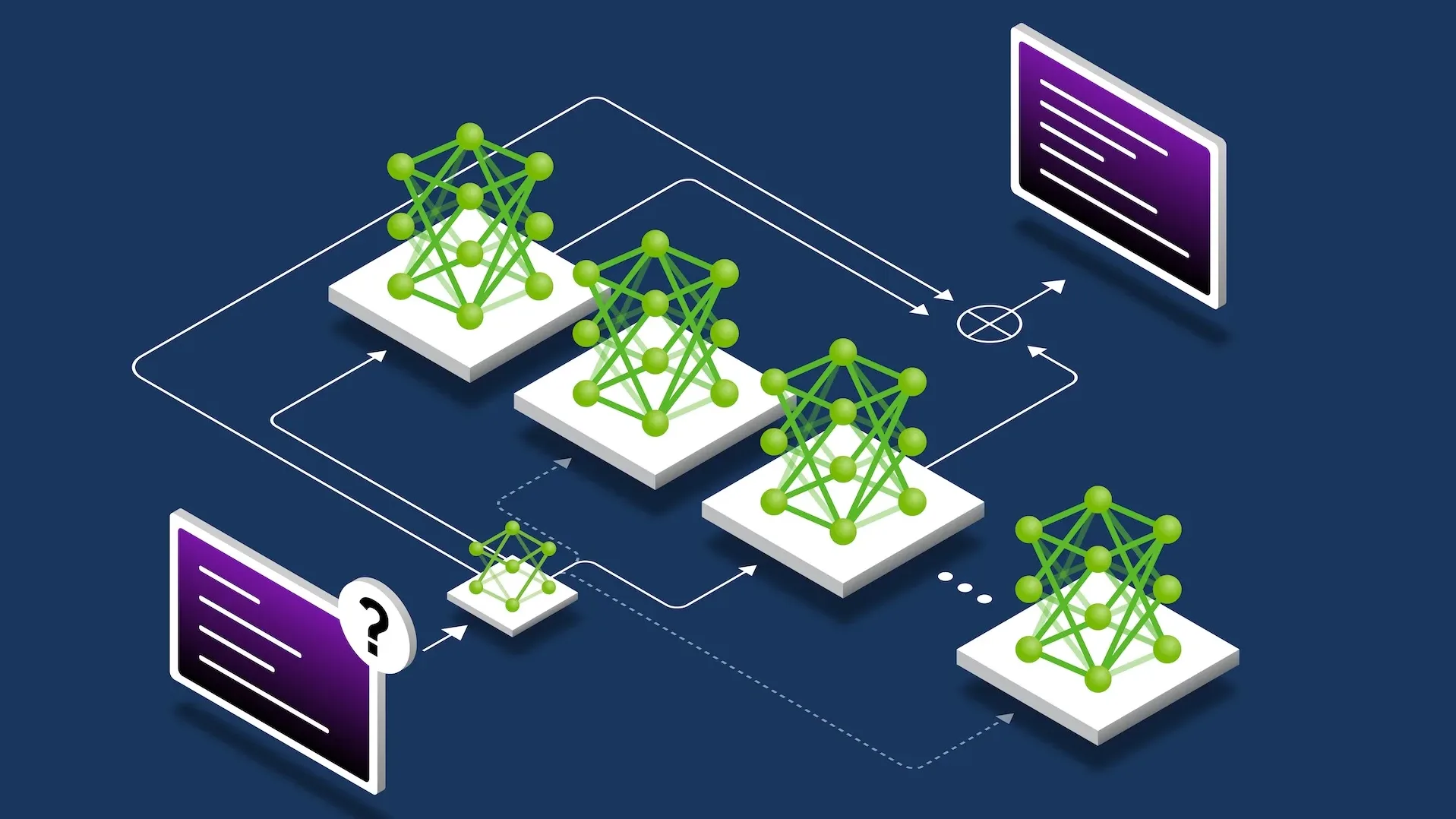
Deploying Disaggregated LLM Inference Workloads on Kubernetes
As large language model (LLM) inference workloads grow in complexity, a single monolithic serving process starts to hit its limits. Prefill and decode stages...