JUNE 15–18|SAN FRANCISCO
Join us at the world’s largest data, apps and AI event.
JUNE 15–18|SAN FRANCISCO
Join us at the world’s largest data, apps and AI event.
Lessons from building reliable LLM inference infrastructure
Building reliable LLM inference infrastructure for our enterprise customers requires innovations in load balancing, inference resilience, and performance optimizations
JUNE 15–18|SAN FRANCISCO
Join us at the world’s largest data, apps and AI event.
JUNE 15–18|SAN FRANCISCO
Join us at the world’s largest data, apps and AI event.
Lessons from building reliable LLM inference infrastructure
Learn how prompt caching speeds up OSS LLM inference on Databricks, and delivers secure, automatic performance gains.
How we serve a large variety of custom AI models without asking customers to tune infrastructure, at 300K+ QPS, under 10ms…

News and tutorials for developers, scientists, and IT admins

Deploying large language models (LLMs) requires large-scale distributed inference, which spreads model computation and request…
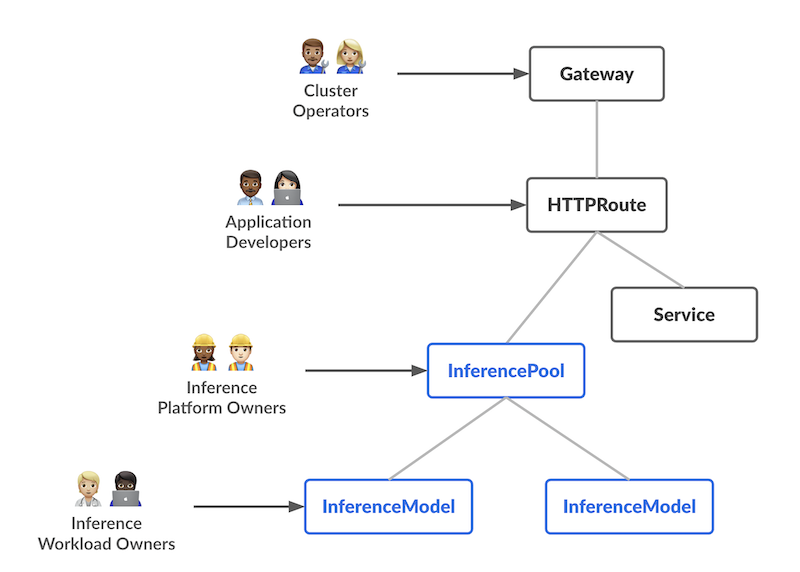
Modern generative AI and large language model (LLM) services create unique traffic-routing challenges on Kubernetes. Unlike…

As large language model (LLM) inference workloads grow in complexity, a single monolithic serving process starts to hit its…