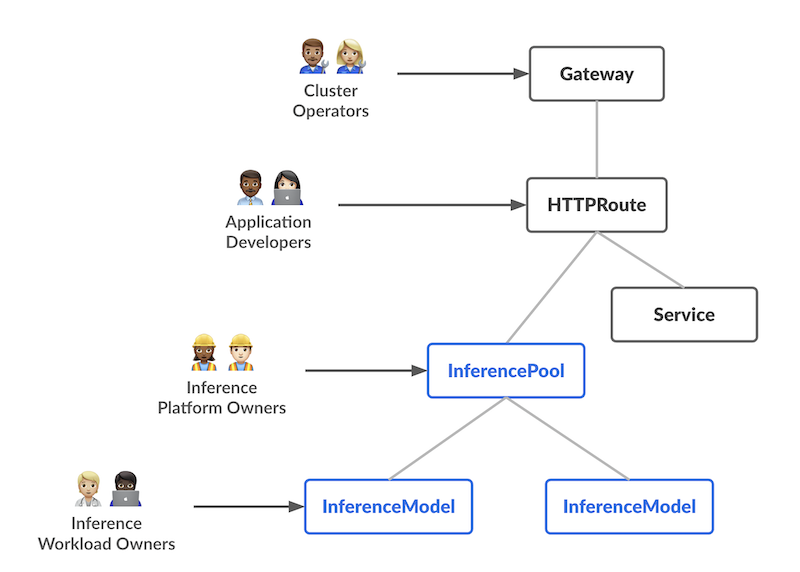
By Daneyon Hansen (Solo.io), Kaushik Mitra (Google), Jiaxin Shan (Bytedance), Kellen Swain (Google) |
Thursday, June 05, 2025Modern generative AI and large language model (LLM) services create unique traffic-routing challenges
on Kubernetes. Unlike typical short-lived, stateless web requests, LLM inference sessions are often
long-running, resource-intensive, and partially stateful. For example, a single GPU-backed model server
may keep multiple inference sessions active and maintain in-memory token caches.Traditional load balancers focused on HTTP path or round-robin lack the specialized capabilities needed





