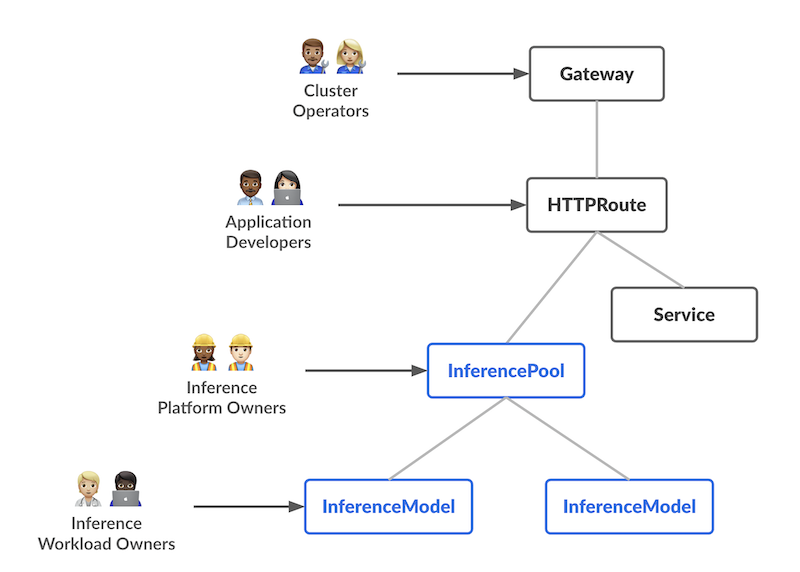
The request arrives. The model answers. For most teams, everything in between is invisible — a gateway rule, a load balancer entry, maybe a classifier someone wrote three months ago. That worked when inference meant one cluster and one model family. The execution environment was fixed, so the routing decision was trivial.
That assumption is gone. Enterprise inference now spans GPU clusters, dedicated inference silicon, giant-context processors, provider APIs, and sovereign on-premises substrates — each with different physics, different cost models, and different failure domains. Every routing decision is now implicitly a placement decision. And the application layer was never designed to make it correctly.
Inference placement orchestration is the discipline of governing those decisions at the infrastructure level — where the signals, the authority, and the system visibility actually exist.
Note: Cost-aware model routing asks: which model should answer this request? Infrastructure-aware inference placement asks: where should this request execute — on which substrate, under which topology, within which latency and sovereignty constraints? Those are no longer the same problem. The first is covered in Cost-Aware Model Routing in Production. This post covers the second.