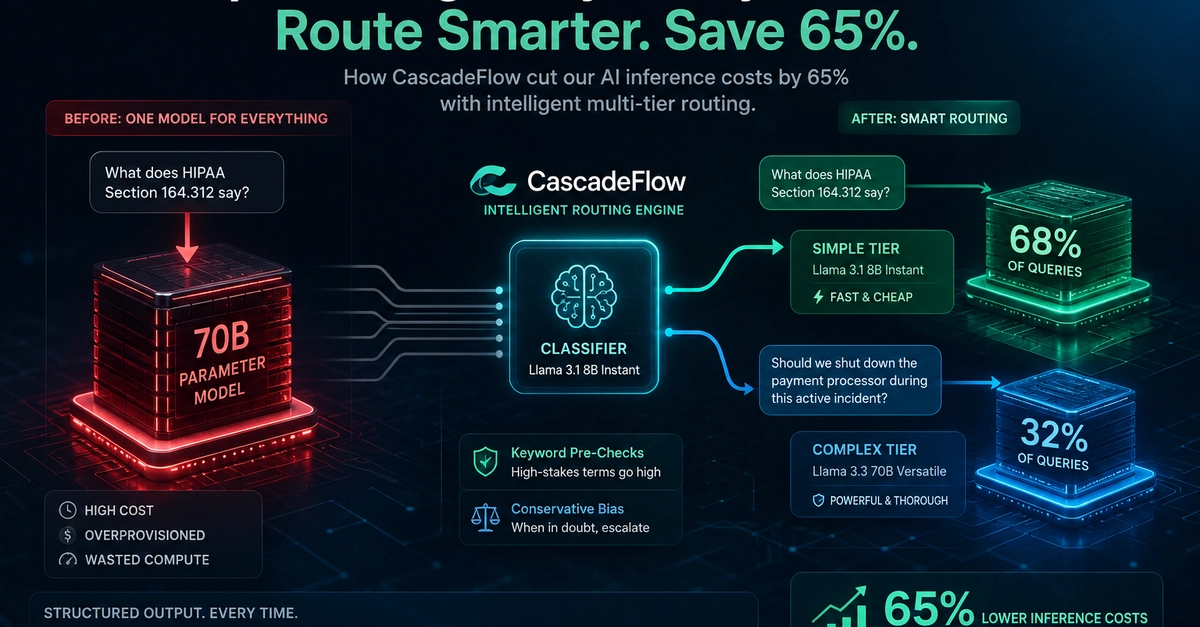
Every query hitting our AI layer was going straight to the most powerful model we had. A user asking "what does HIPAA Section 164.312 say?" got the same compute budget as one asking "should we shut down the payment processor during this active incident?" That was expensive and stupid, and it took embarrassingly long to fix.
This is the story of how we built a routing layer called CascadeFlow into SentinelOps AI, an enterprise decision intelligence platform, and what actually happened when we turned it on.
The Problem With "One Model Fits All"
When you're building an AI system for enterprise operations teams—people making real decisions about infrastructure, compliance posture, and incident response—you face a genuine tension. You need the model to be good when it matters. But "good" on a documentation lookup is a different thing from "good" on "we have a potential SOC2 violation, walk me through the remediation path."
Before routing, every query went to our primary reasoning model (Llama 3.3 70B via Groq). The latency was fine. The quality was fine. The cost was not fine. At scale, routing simple factual queries through a 70B parameter model is just burning money.