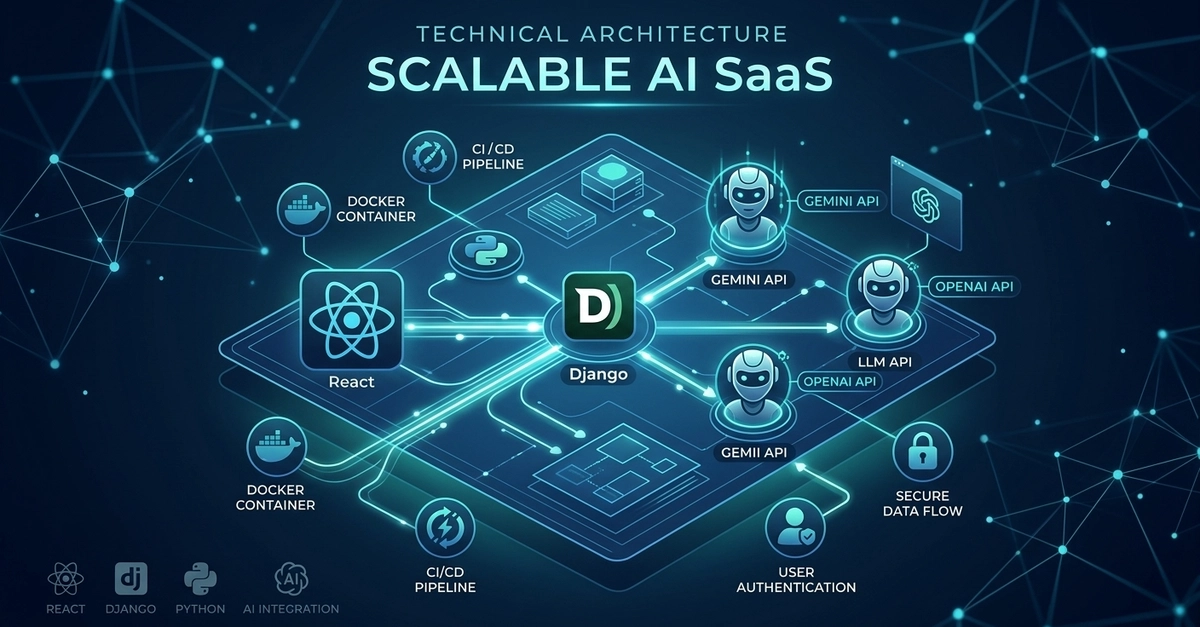
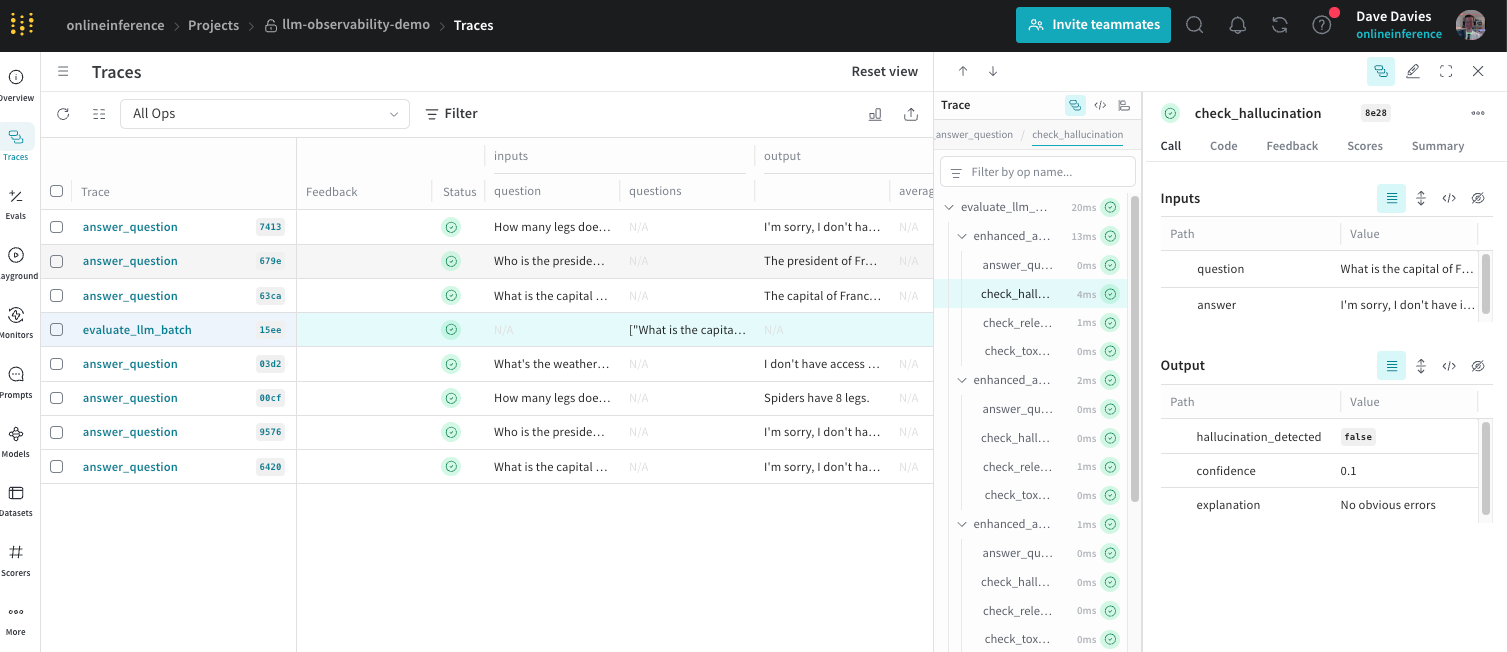
Deploying large language models (LLMs) at scale on Amazon SageMaker AI Inference makes observability a critical pillar of any production machine learning (ML) strategy. Unlike conventional software that returns deterministic outputs, LLMs generate variable, free-form responses that are difficult to validate with standard metrics. LLM output quality can change over time as input distributions shift, and quality monitoring helps detect these changes early. For generative AI workloads, observability also includes the model serving infrastructure, where unpredictable token consumption, GPU memory pressure, and latency spikes make capacity planning and cost control a moving target.
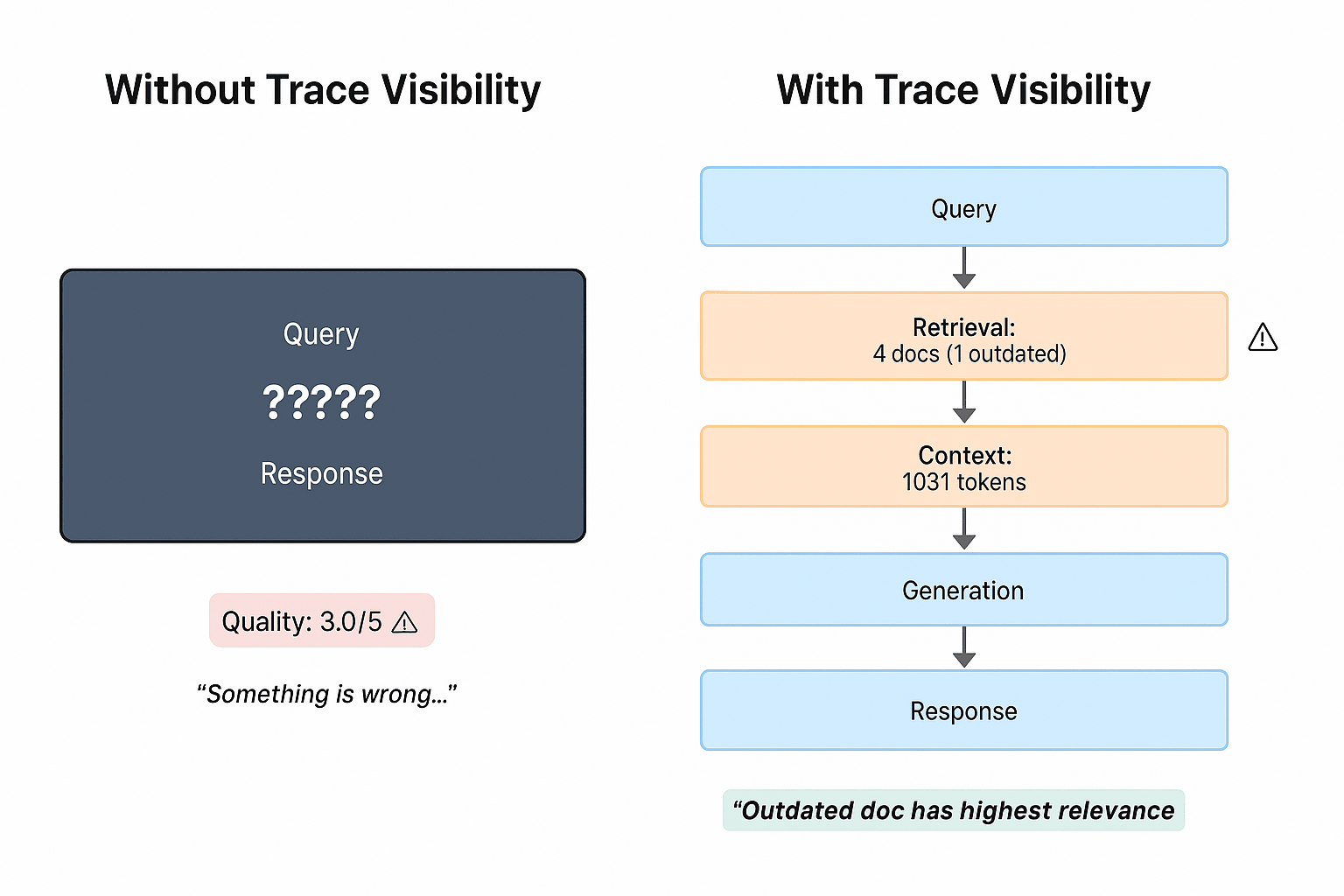
A comprehensive observability approach for LLM inference must address two distinct but complementary dimensions: model serving infrastructure (quantity) and LLM quality. Quantity monitoring focuses on the operational health of inference infrastructure, tracking request throughput and resource utilization. These metrics help detect bottlenecks, right-size compute resources, and control costs. Quality monitoring focuses on the performance of the LLMs themselves, evaluating response accuracy, compliance, and consistency over time.