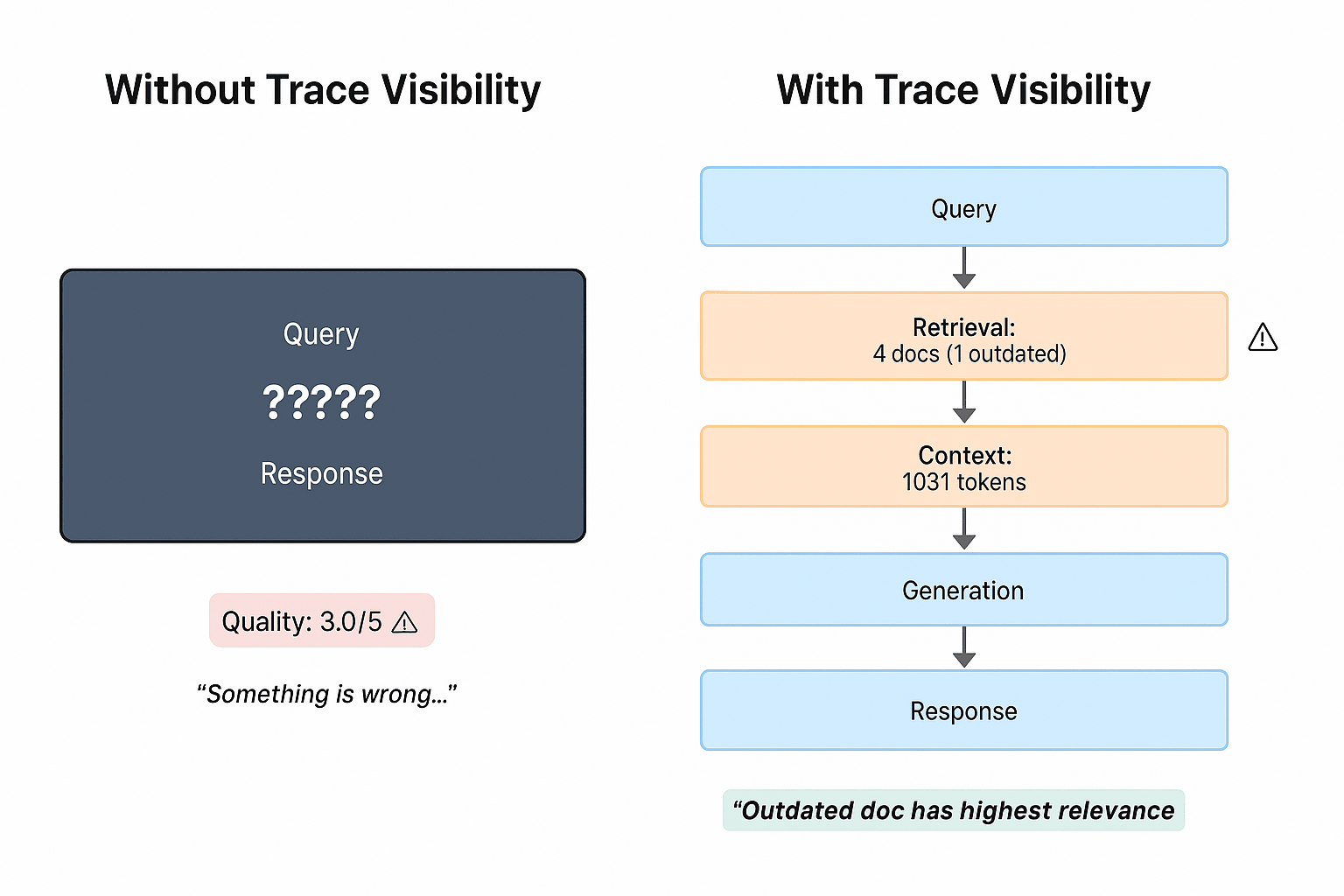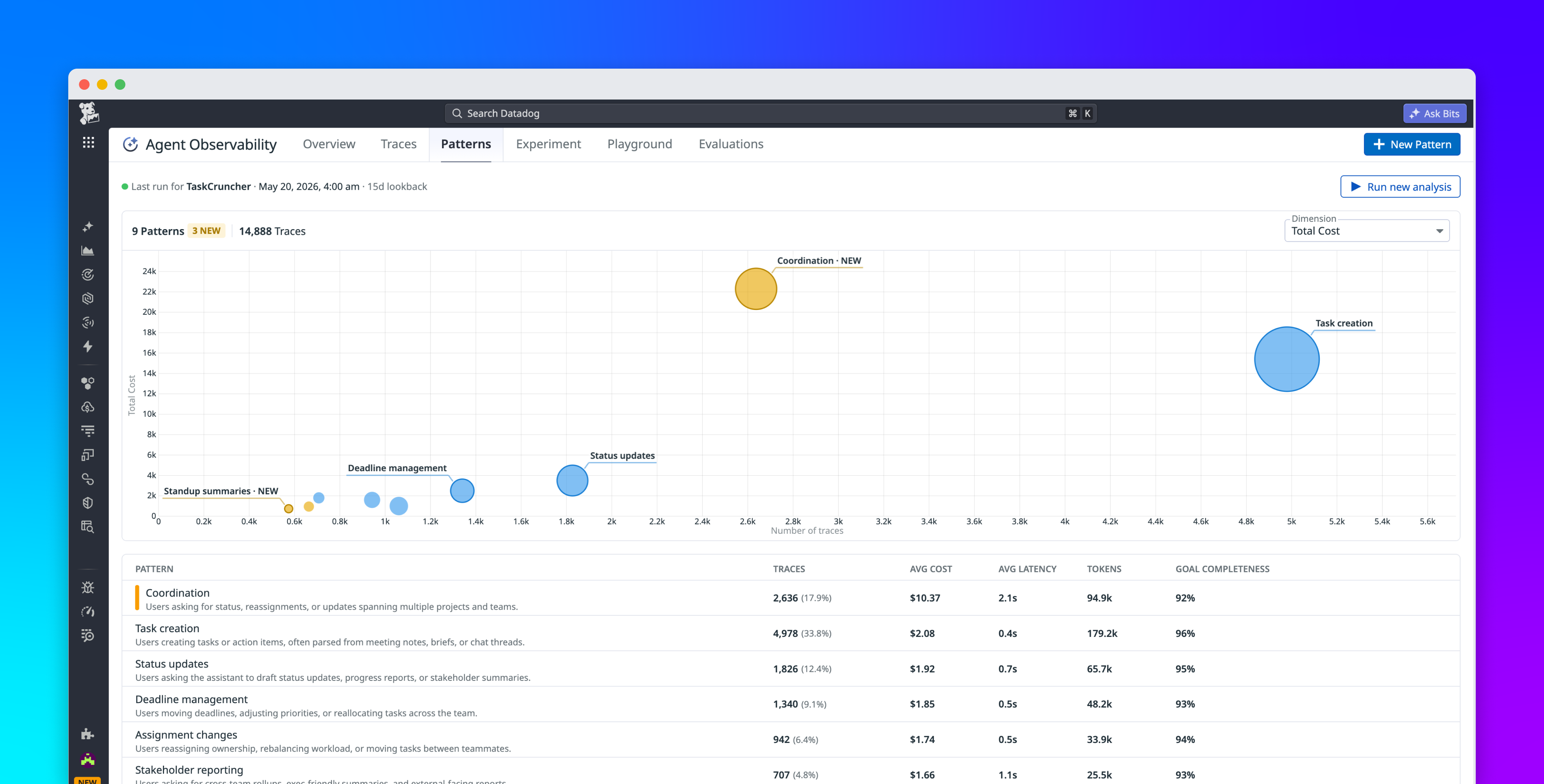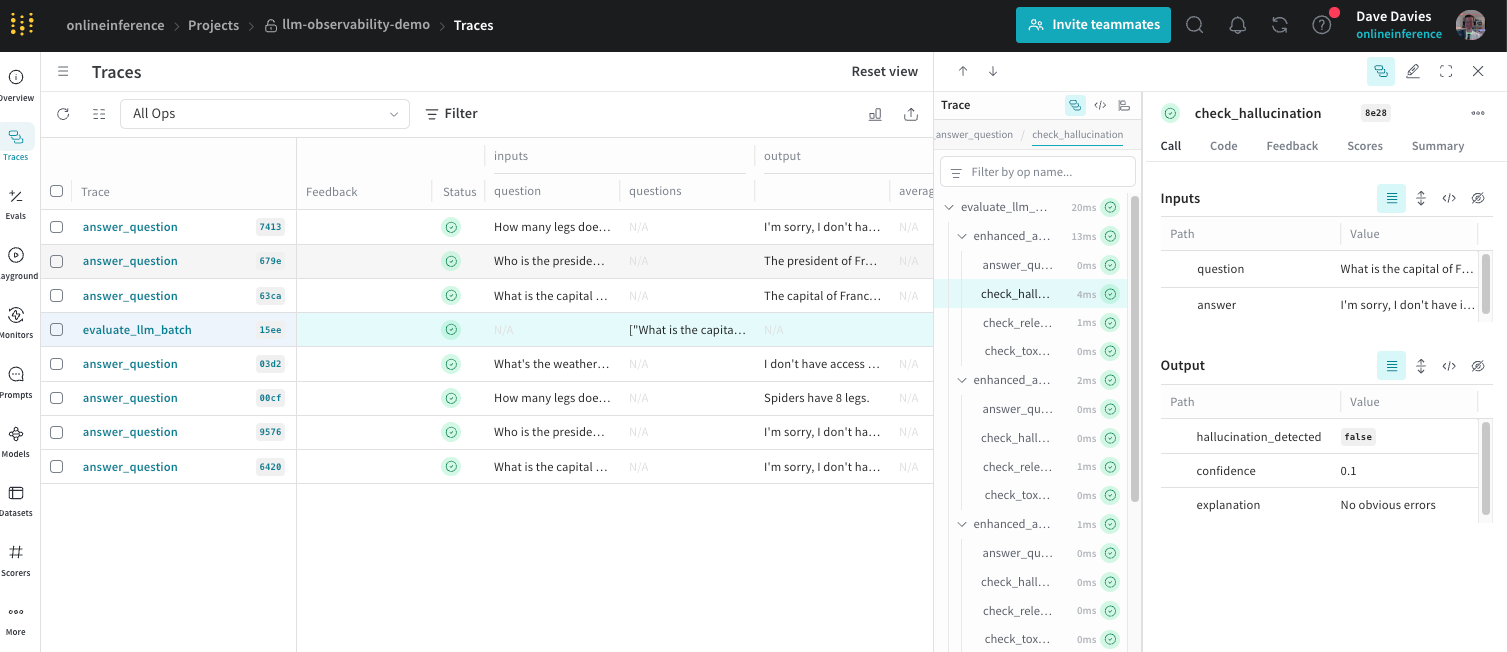
Large language models likeGPT-4o andLLaMAare powering a new wave of AI applications, from chatbotsand coding assistantsto research tools. However, deploying these LLM-powered applications in production is far more challenging than traditional software or even typical machine learning systems.LLMs are massive and non-deterministic, often behaving as black boxes with unpredictable outputs. Issues such as false or biased answers can arise unexpectedly, and performance or cost can spiral if not managed. This is where LLM observability comes in.In this article, we will explain what LLM observability is and why it matters for managing LLM applications. We will explore common problems like hallucinations and prompt injection, distinguish observability from standard monitoring, and discuss the key challenges in debugging LLM systems. We will also highlight critical features to look for in LLM observability tools. Finally, we will walk through a simple tutorial usingW&B Weave to track outputs, detect anomalies, and visualize metrics.What is LLM observability?LLM observability refers to the tools, practices, and infrastructure that give you visibility into every aspect of an LLM application’s behavior – from its technical performance (like latency or errors) to the quality of the content it generates. In simpler terms, it means having the ability to monitor, trace, and analyze how your LLM system is functioning and why it produces the outputs that it does.Unlike basic monitoring that might only track system metrics, LLM observability goes deeper to evaluate whether the model’s outputs are useful, accurate, and safe. It creates a feedback loop where raw data from the model is turned into actionable insights for developers and ML engineers.Common issues in LLM applicationsEven advanced LLMs can exhibit a variety of issues when deployed. Below are some of the common problems that necessitate careful observability:Hallucinations: LLMs sometimes generate information that is factually incorrect or entirely fabricated, despite sounding confident.Prompt injection attacks: A security issue where a user intentionally crafts an input that manipulates the LLM into deviating from its intended behavior.Latency and performance bottlenecks: Users might experience slow responses if the model or its pipeline isn’t optimized.Cost unpredictability: Applications may face rising costs if token consumption is not monitored.Bias and toxicity: LLMs can inadvertently produce biased, offensive, or inappropriate content based on their training data.Security & privacy risks: The model might inadvertently leak sensitive data provided in its context.LLM observability vs. LLM monitoringLLM Monitoring focuses on the what. It tracks performance metrics in real time like response latency, error rates, and token counts.LLM Observability focuses on the why. It provides full visibility into all moving parts, allowing engineers to reconstruct the path of a specific query through the system to find the root cause of an error.Key Features to Look ForFeaturePurposeTracing & LoggingCapture each step in LLM pipelines (prompts, tool uses) as a trace.Output EvaluationEvaluate quality using automated metrics or human feedback.Anomaly DetectionAutomatically flag spikes in toxicity or abnormal output lengths.Tutorial: Tracking LLM outputs with W&B WeaveWeave is a toolkit that helps developers instrument and monitor LLM applications by capturing traces of function calls.1. Install and initialize W&B Weavepip install weave wandb
LLM observability: Your guide to monitoring AI in production
Large language models likeGPT-4o andLLaMAare powering a new wave of AI applications, from chatbotsand coding assistantsto research tools. However, deploying these LLM-powered applications in production is far more challenging than traditional software or even typical machine learning systems.LLMs are massive and non-deterministic, often behaving as black boxes with unpredictable outputs. Issues such as false or biased answers can arise unexpectedly, and performance or cost can spiral if not managed. This is where LLM observability comes in.In this article, we will explain what LLM observability is and why it matters for managing LLM applications. We will explore common problems like hallucinations and prompt injection, distinguish observability from standard monitoring, and discuss the key challenges in debugging LLM systems. We will also highlight critical features to look for in LLM observability tools. Finally, we will walk through a simple tutorial usingW&B Weave to track outputs, detect anomalies, and visualize metrics.What is LLM observability?LLM observability refers to the tools, practices, and infrastructure that give you visibility into every aspect of an LLM application’s behavior – from its technical performance (like latency or errors) to the quality of the content it generates. In simpler terms, it means having the ability to monitor, trace, and analyze how your LLM system is functioning and why it produces the outputs that it does.Unlike basic monitoring that might only track system metrics, LLM observability goes deeper to evaluate whether the model’s outputs are useful, accurate, and safe. It creates a feedback loop where raw data from the model is turned into actionable insights for developers and ML engineers.Common issues in LLM applicationsEven advanced LLMs can exhibit a variety of issues when deployed. Below are some of the common problems that necessitate careful observability:Hallucinations: LLMs sometimes generate information that is factually incorrect or entirely fabricated, despite sounding confident.Prompt injection attacks: A security issue where a user intentionally crafts an input that manipulates the LLM into deviating from its intended behavior.Latency and performance bottlenecks: Users might experience slow responses if the model or its pipeline isn’t optimized.Cost unpredictability: Applications may face rising costs if token consumption is not monitored.Bias and toxicity: LLMs can inadvertently produce biased, offensive, or inappropriate content based on their training data.Security & privacy risks: The model might inadvertently leak sensitive data provided in its context.LLM observability vs. LLM monitoringLLM Monitoring focuses on the what. It tracks performance metrics in real time like response latency, error rates, and token counts.LLM Observability focuses on the why. It provides full visibility into all moving parts, allowing engineers to reconstruct the path of a specific query through the system to find the root cause of an error.Key Features to Look ForFeaturePurposeTracing & LoggingCapture each step in LLM pipelines (prompts, tool uses) as a trace.Output EvaluationEvaluate quality using automated metrics or human feedback.Anomaly DetectionAutomatically flag spikes in toxicity or abnormal output lengths.Tutorial: Tracking LLM outputs with W&B WeaveWeave is a toolkit that helps developers instrument and monitor LLM applications by capturing traces of function calls.1. Install and initialize W&B Weavepip install weave wandb