For more information or if you need help retrieving your data, please contact Weights & Biases Customer Support at support@wandb.com
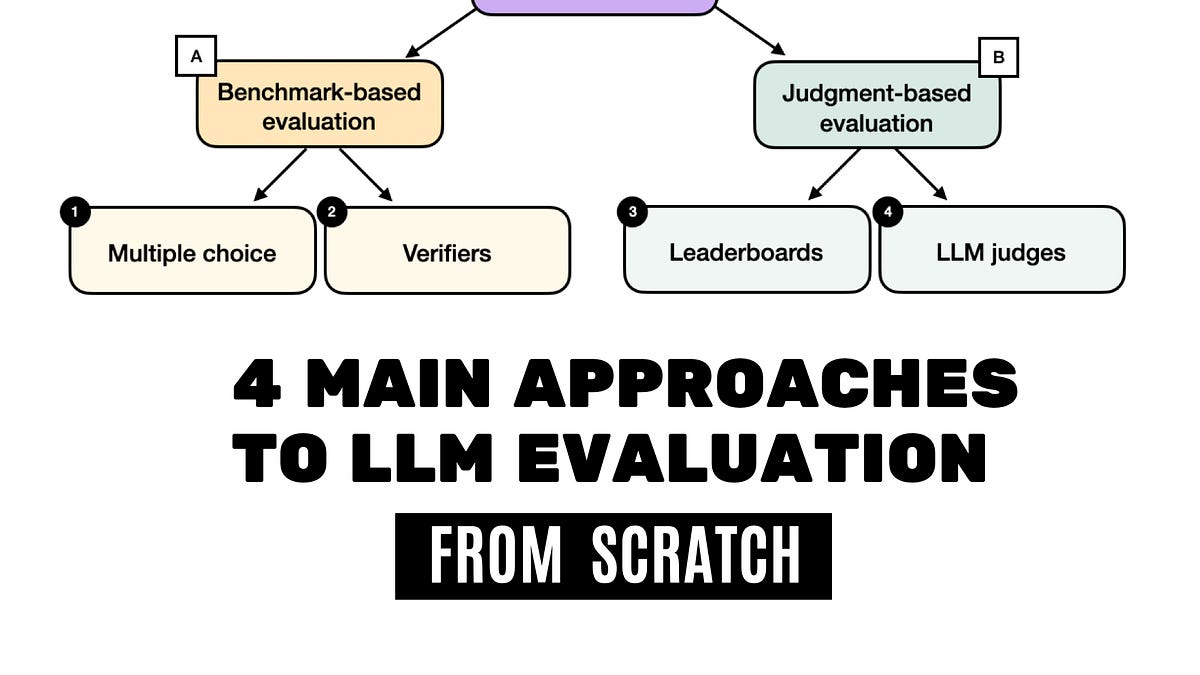
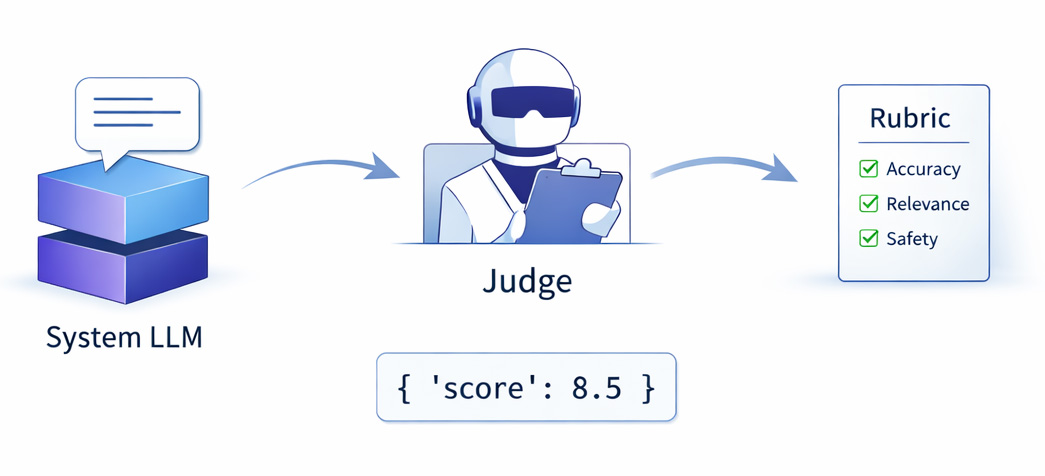
LLM-as-a-judge refers to using large language models to evaluate the outputs of other AI systems by scoring responses for accuracy, relevance, safety, or any other user-specified criteria. These judge models leverage language understanding to make nuanced judgments about quality, much like a human evaluator would.
This approach has rapidly gained traction because it solves a fundamental problem in AI development: how do you evaluate systems at scale when human review is too slow and expensive and traditional metrics are too rigid? Consider the challenge of assessing a RAG system’s answers, or a chatbot’s helpfulness. Human evaluation provides gold-standard quality but does not scale beyond a few hundred examples. Rule-based metrics like BLEU or ROUGE capture surface patterns and miss semantic meaning entirely.
LLM-as-a-judge bridges this gap by delivering human-like judgments at machine speed and cost.
Its versatility extends across the entire AI development lifecycle. In evaluation, judge models assess whether answers are correct and whether they meet quality criteria like helpfulness and clarity, or violate anti-criteria like toxicity and hallucination. In training, judges generate preference pairs for RLHF (Reinforcement Learning from Human Feedback) and GRPO (Group Relative Policy Optimization), rapidly labeling thousands of examples to accelerate model improvement. In production applications, judges monitor responses in real-time, acting as quality filters and guardrails that block unsafe outputs or trigger fallback behaviors when quality drops.