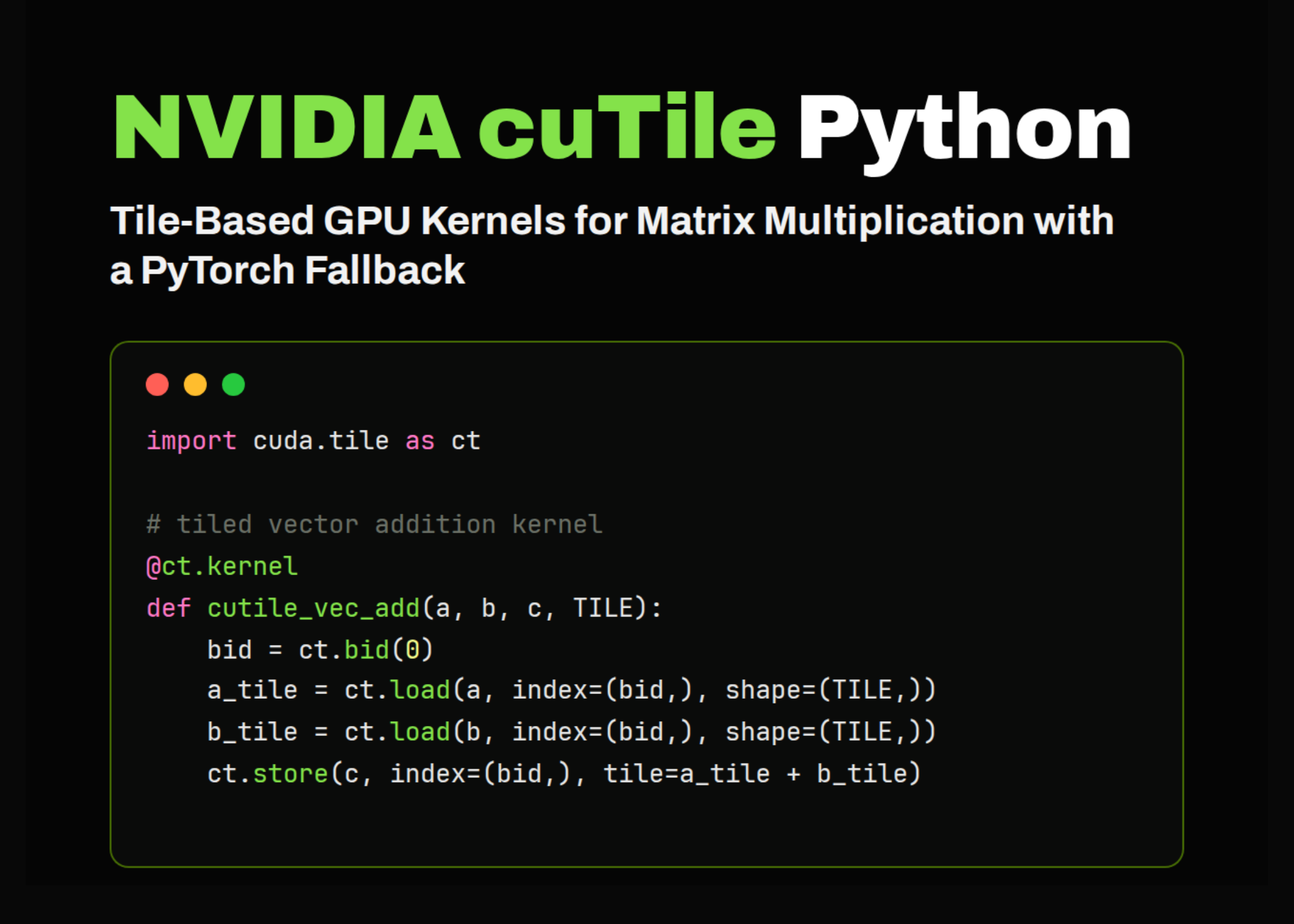
In this tutorial, we delve into CuPy as a powerful GPU-accelerated alternative to NumPy for high-performance numerical computing in Python. We start by inspecting the available CUDA device, checking the CuPy version, runtime details, GPU memory, and compute capability so that we understand the hardware environment before running heavy computations. Then, we compare NumPy and CuPy on large matrix multiplication and FFT workloads to see how GPU acceleration changes execution speed. Also, we work with memory pools, custom elementwise kernels, reduction kernels, raw CUDA kernels, CUDA streams, sparse matrices, dense linear solvers, GPU image processing, DLPack interoperability, event-based profiling, cupyx.jit, and kernel fusion. Through these examples, we build a practical understanding of how CuPy lets us write familiar Python code while still accessing advanced CUDA-level performance features.
import sys, time, subprocess
try:
import cupy as cp
except ImportError: