NVIDIA CUDA 13.3 brings new capabilities and performance optimizations to developers across the CUDA ecosystem. The launch of NVIDIA CUDA Tile programming in C++, enables high-level, tile-based kernel development that automatically manages complex low-level GPU details for optimal performance and portability. Additionally, CUDA Tile programming is now supported on Compute Capability 9.0 (NVIDIA Hopper) GPUs in addition to all other supported GPU architectures.
We are also releasing CUDA Python 1.0, solidifying the support and stability of the CUDA Python SW ecosystem, and introducing critical features like green contexts and process checkpointing.
For performance enthusiasts, the newly launched NVIDIA CompileIQ compiler auto-tuning framework delivers up to a 15% speedup on critical kernels like GEMM and attention. This release also features official C++23 support in NVCC, expanded tensor interoperability with DLPack/mdspan in CCCL 3.3, and numerous updates to the math libraries (cuBLAS, cuSPARSE, cuSOLVER) and profiling tools (Nsight Compute and Nsight Systems).
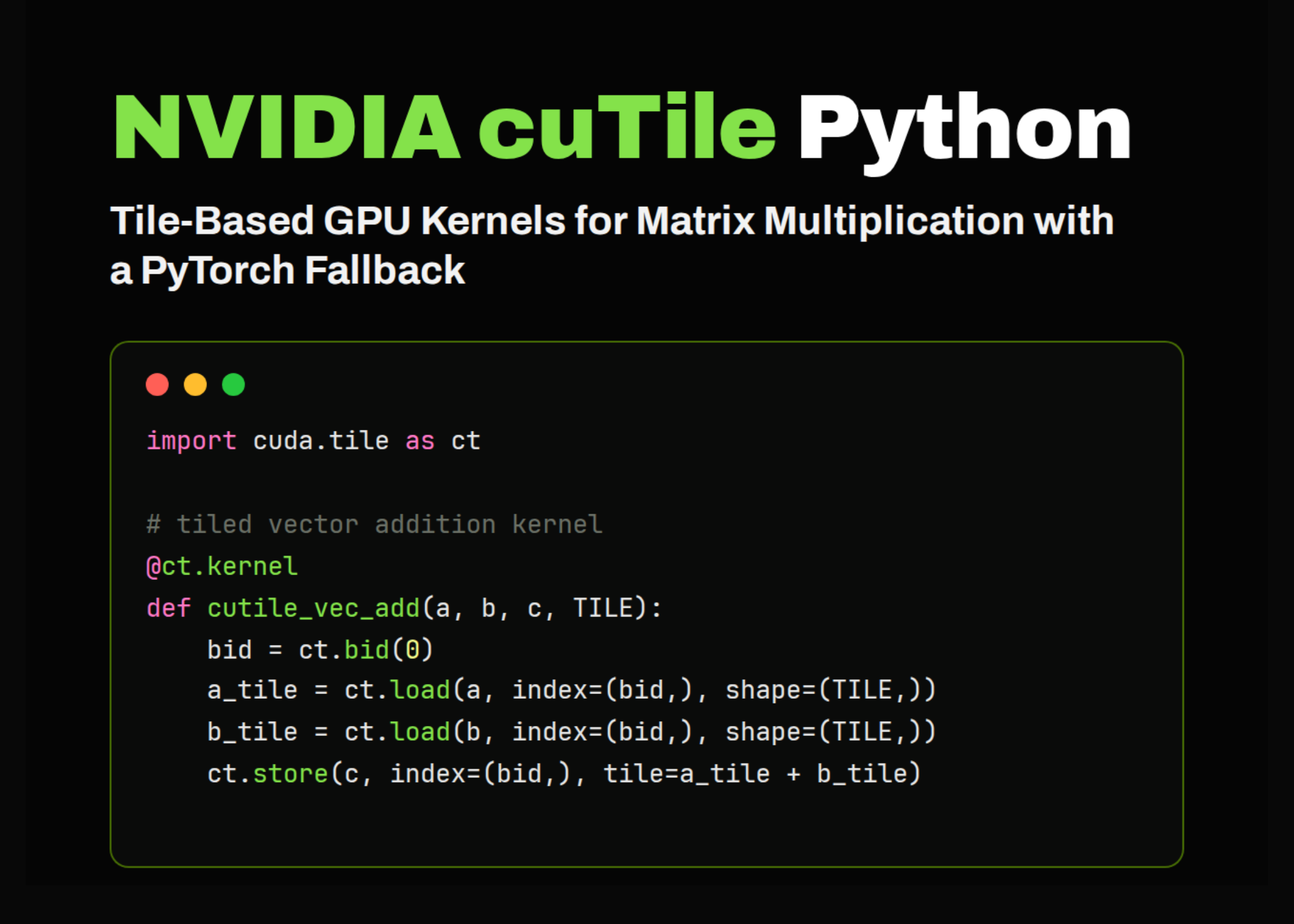
Release of CUDA Tile C++
With the release of CUDA 13.3, CUDA Tile support is extended to C++, enabling the large existing C++ codebase and developer base to create highly-optimized GPU tile kernels. This model automates parallelism, memory movement, asynchrony, and other low-level details, resulting in C++ code that is portable across NVIDIA GPU architectures. For more information, check out our blog post.