Developers can now use NVIDIA CUDA Tile programming within large existing C++ GPU codebases to develop highly optimized GPU kernels using tile-based abstractions.
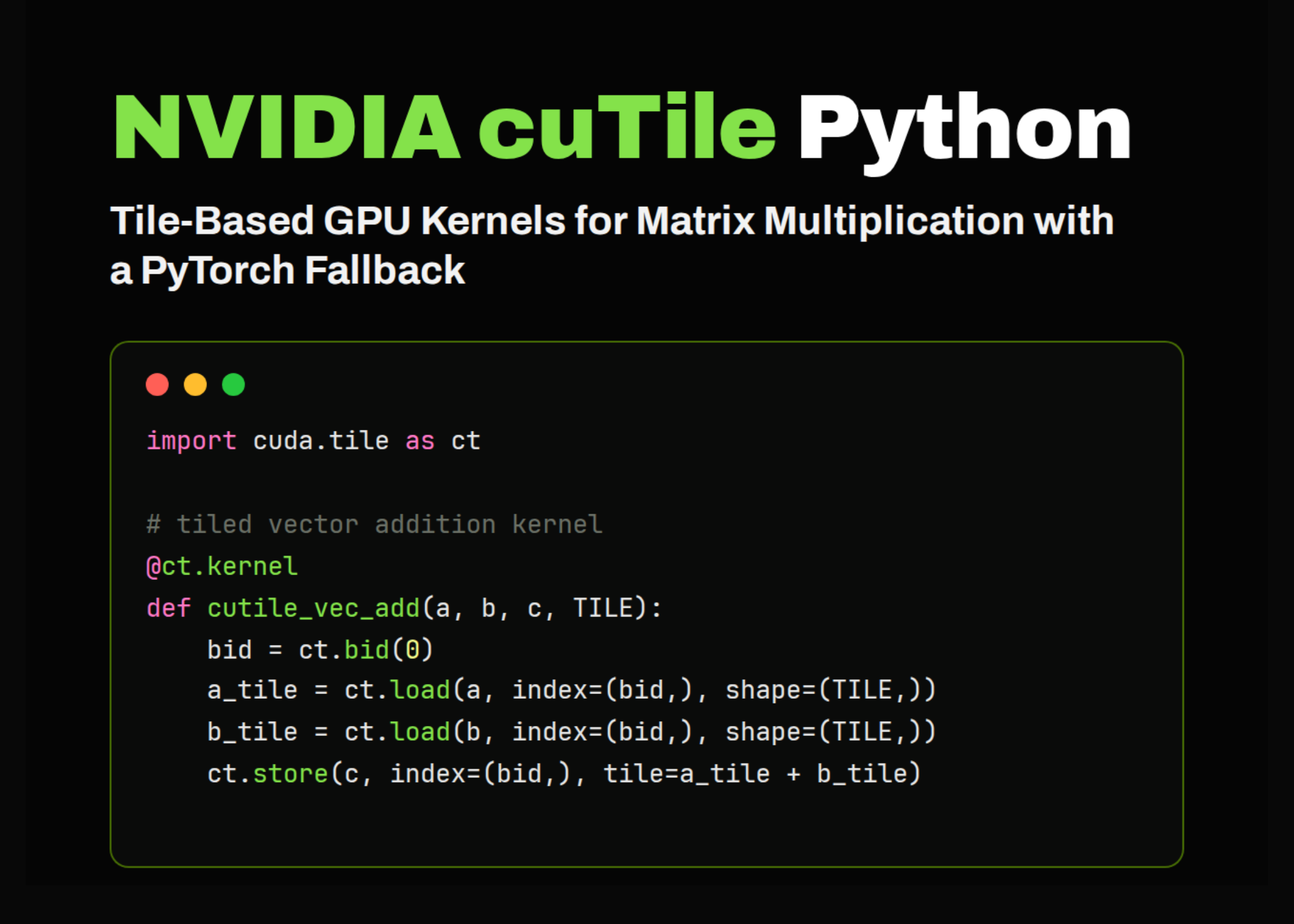
NVIDIA CUDA Tile, launched with NVIDIA CUDA 13.1, introduced tile-based programming for GPUs. Designed with a top-level language layer and another intermediate layer that any high-level programming language can target, CUDA Tile automatically makes use of the advanced capabilities of NVIDIA hardware—including tensor cores, shared memory, and tensor memory accelerators—without requiring the application to target them directly.
Python was the first language supported for tile-based GPU applications. The newly released CUDA 13.3 adds support for writing tile kernels in C++, enabling developers to build highly optimized GPU kernels.
What is CUDA Tile C++?
CUDA Tile C++ is an expression of the CUDA Tile programming model in C++, built on top of the CUDA Tile IR specification. It enables developers to write tile kernels in C++ and express GPU kernels using a tile-based model, rather than or in addition to a single instruction, multiple threads (SIMT) model.