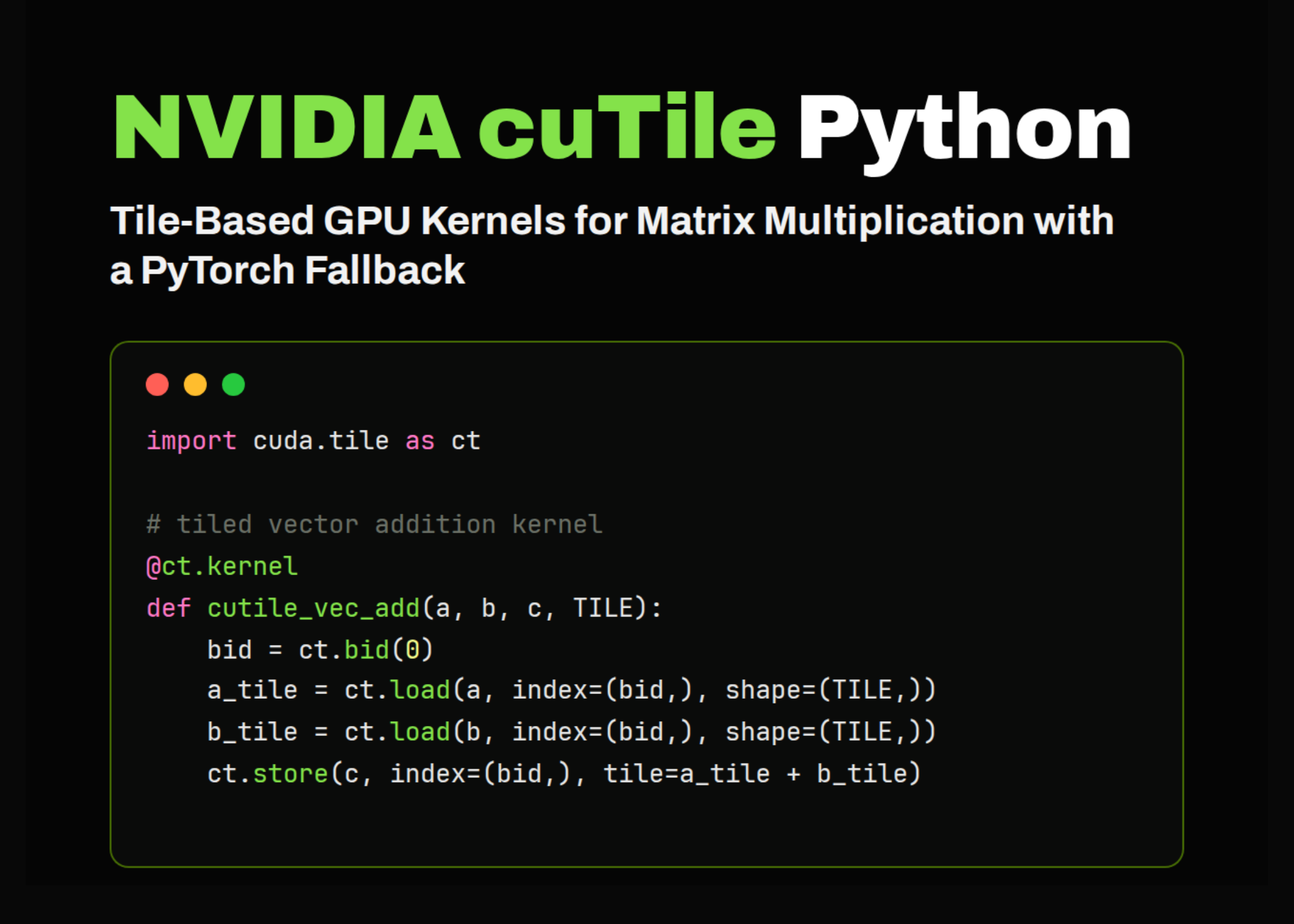
NVIDIA CUDA Tile (cuTile) is a tile-based programming model that enables developers to write GPU kernels in terms of tile-level operations—loads, stores, and matrix multiply-accumulate—rather than manually coordinating threads, warps, and shared memory.
cuTile.jl brings the same tile-based approach to the dynamic programming language Julia. Users can write custom GPU kernels without dropping down to NVIDIA CUDA C++. Custom kernels are often essential in Julia’s scientific computing ecosystem— spanning differential equations, probabilistic programming, and physics simulations.
cuTile Python has a growing library of optimized kernels for GPU acceleration. The ability to translate those kernels to cuTile.jl provides the Julia ecosystem with immediate access to battle-tested implementations, instead of rewriting each one from scratch.
This post covers cross-domain-specific language (DSL) GPU kernel translation, from porting cuTile Python kernels to cuTile.jl (Julia). It shows how to:
Translate GPU kernels between cuTile Python and cuTile.jl: Walk through a complete matrix multiplication example side-by-side.