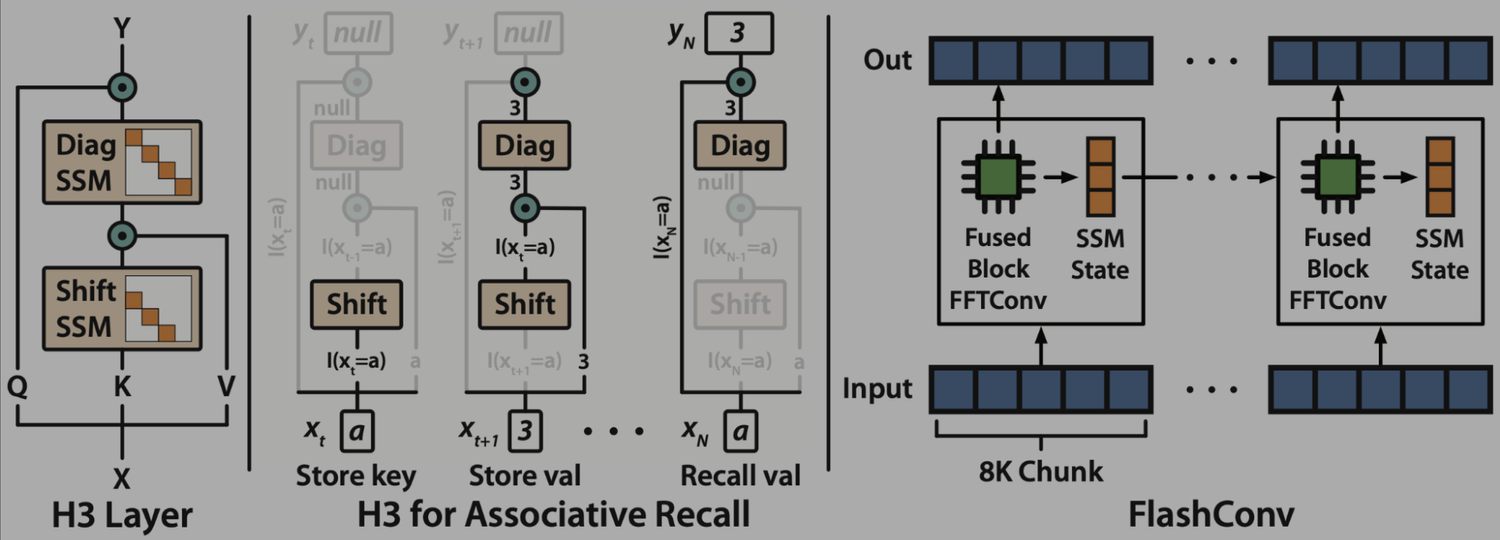
Convolution models with long filters now have state-of-the-art reasoning abilities in many long-sequence tasks, from long-range language modeling to audio analysis and DNA modeling. But they lag behind the most optimized Transformers in wall-clock time. A major bottleneck is the Fast Fourier Transform (FFT), which allows long convolutions to run in $O(N \log N)$ time in sequence length $N$ but has poor hardware utilization. We propose FlashFFTConv, a new algorithm for efficiently computing the FFT convolution on GPUs. FlashFFTConv speeds up convolutions by up to 7.93x over PyTorch and achieves up to 4.4x speedup end-to-end. Starting at sequence length 2K, FlashFFTConv starts to match the performance of FlashAttention-v2 – and outperforms it for longer sequences, achieving up to 62% MFU.Paper: FlashFFTConv: Efficient Convolutions for Long Sequences with Tensor Cores. Daniel Y. Fu*, Hermann Kumbong*, Eric Nguyen, Christopher Ré. arXiv linkTry it now: https://github.com/HazyResearch/flash-fft-convFlashFFTConv: Efficient Convolutions for Long Sequences with Tensor CoresOver the past few years, we've seen convolutional sequence models take the world of long-sequence modeling by storm. From S4 and follow-ups like S5 and SS, to gated architectures like Monarch Mixer, BiGS, Hyena, and GSS, to hybrid architectures like Mega, H3, and Liquid-S4 – long convolutional models have had a major impact and are here to stay. These models are exciting because they are sub-quadratic in sequence length – thanks to the FFT convolution algorithm, they can be computed in $O(N \log N)$ time in sequence length $N$:def conv(u, k):
FlashFFTConv: Efficient Convolutions for Long Sequences with Tensor Cores
Convolution models with long filters now have state-of-the-art reasoning abilities in many long-sequence tasks, from long-range language modeling to audio analysis and DNA modeling. But they lag behind the most optimized Transformers in wall-clock time. A major bottleneck is the Fast Fourier Transform (FFT), which allows long convolutions to run in $O(N \log N)$ time in sequence length $N$ but has poor hardware utilization. We propose FlashFFTConv, a new algorithm for efficiently computing the FFT convolution on GPUs. FlashFFTConv speeds up convolutions by up to 7.93x over PyTorch and achieves up to 4.4x speedup end-to-end. Starting at sequence length 2K, FlashFFTConv starts to match the performance of FlashAttention-v2 – and outperforms it for longer sequences, achieving up to 62% MFU.Paper: FlashFFTConv: Efficient Convolutions for Long Sequences with Tensor Cores. Daniel Y. Fu*, Hermann Kumbong*, Eric Nguyen, Christopher Ré. arXiv linkTry it now: https://github.com/HazyResearch/flash-fft-convFlashFFTConv: Efficient Convolutions for Long Sequences with Tensor CoresOver the past few years, we've seen convolutional sequence models take the world of long-sequence modeling by storm. From S4 and follow-ups like S5 and SS, to gated architectures like Monarch Mixer, BiGS, Hyena, and GSS, to hybrid architectures like Mega, H3, and Liquid-S4 – long convolutional models have had a major impact and are here to stay. These models are exciting because they are sub-quadratic in sequence length – thanks to the FFT convolution algorithm, they can be computed in $O(N \log N)$ time in sequence length $N$:def conv(u, k):