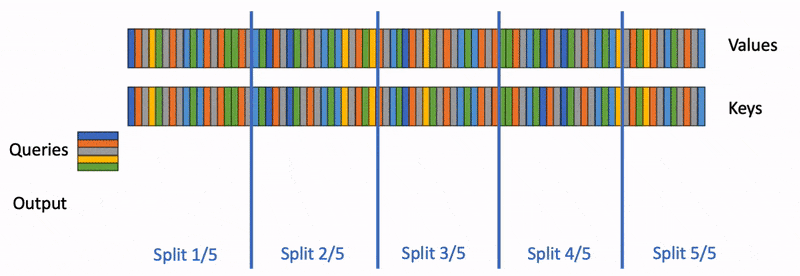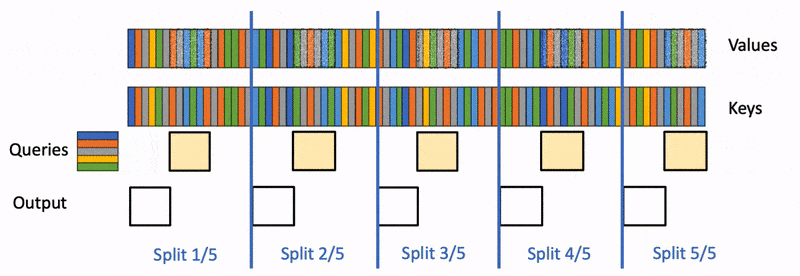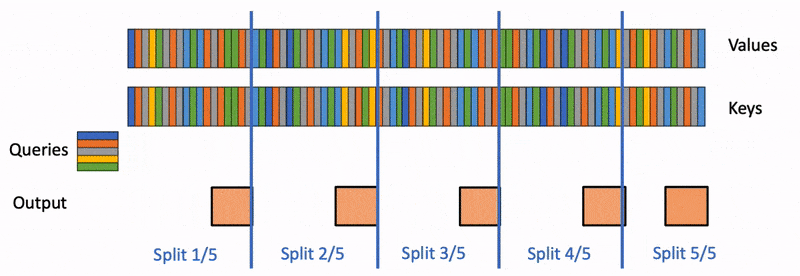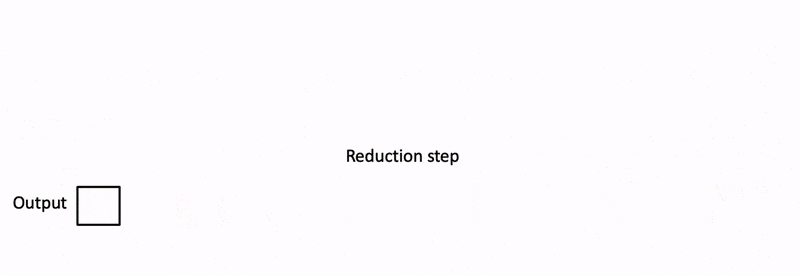
LLMs are getting pulled into longer and messier workflows, handling large inputs and generating longer and longer token sequences. Coding assistants need to keep track of repositories, issue threads, terminal outputs, and earlier edits. Research agents need to carry facts across long documents and tool calls. Deep think systems may generate several parallel chains before settling on an answer.
All of that means more tokens in memory, and more time spent attending to past tokens. In practice, that pushes modern models into a bottleneck that is less about raw model size and more about how they store and read attention state. That state is the key-value cache, or KV cache. It is one of the reasons autoregressive generation is fast enough to be usable at all, but it is also one of the main reasons long-context inference gets expensive and slow.
Recent research shows that if you want better long reasoning and multi-agent workflows, you need to address the attention memory bottleneck and optimize attention while preserving accuracy. And this focus has led to some very interesting “sparse attention” techniques.
Why attention becomes a memory problem
In transformer models, each new token is processed by attention layers that compare the current token’s query vector against key vectors from earlier tokens, and then combine the corresponding value vectors. In autoregressive generation, the model creates text one token at a time, so it would be wasteful to recompute keys and values for the entire prior sequence at every step. Instead, it stores them in the KV cache and reuses them.