This article is part of our coverage of the latest in AI research.
Long-term memory remains a key challenge for large language models. The industry is currently maxing out at effective context windows of around 1 million tokens, which impedes the development of complex applications like massive multi-agent systems and processing very large text corpora.
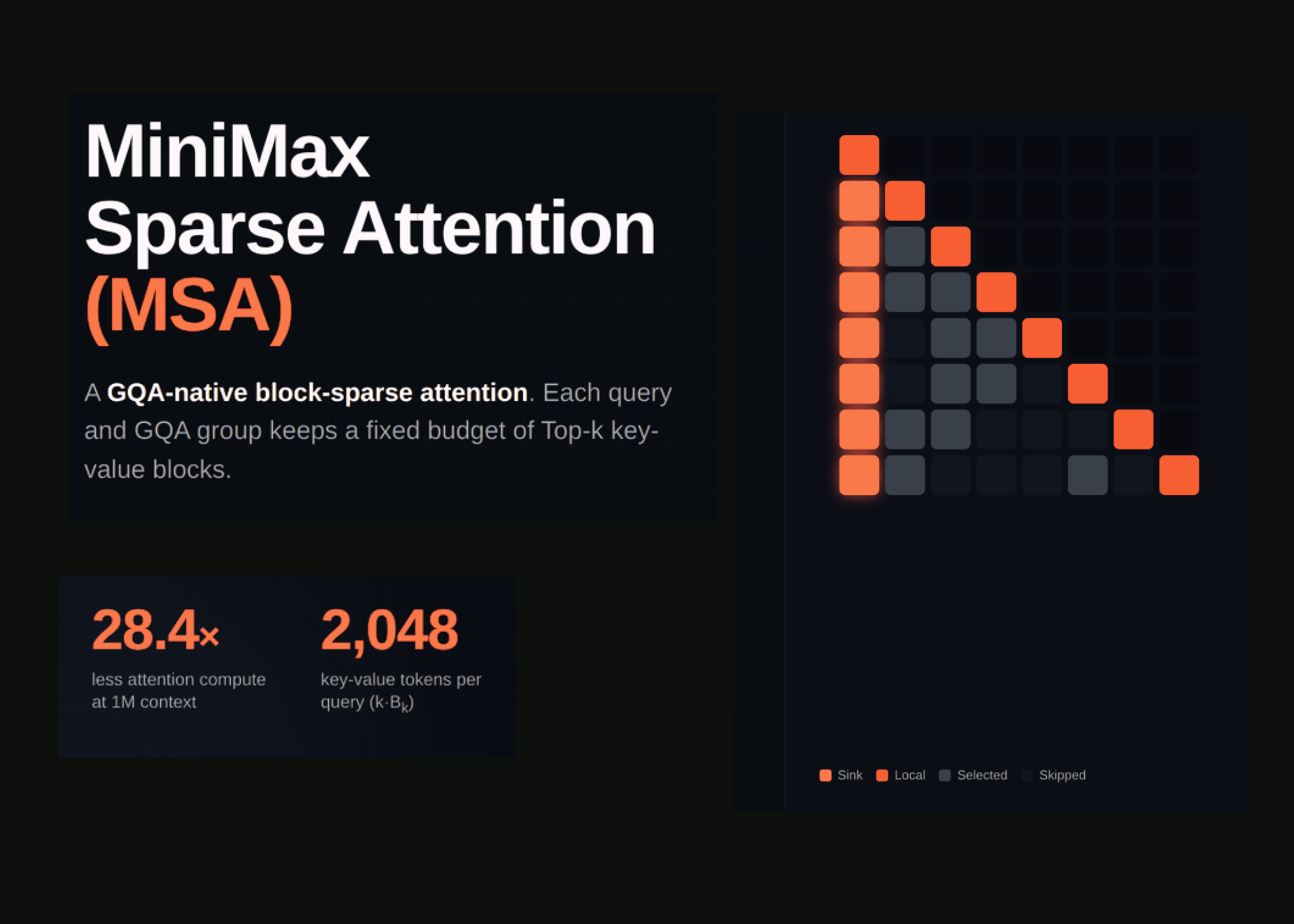
Memory Sparse Attention (MSA), a new technique developed by researchers at Evermind, Shanda Group, and Peking University, addresses the shortcomings of current long-memory solutions. The architecture enables models to extend their context window up to 100 million tokens while preserving their reasoning accuracy.
The key innovation of MSA is a differentiable, end-to-end routing mechanism. The model learns to compress massive document collections into precomputed attention values and retrieve only the most relevant document chunks directly into the model’s active working memory during generation. MSA represents one of several emerging optimization techniques that allow developers to build AI applications capable of handling massive documents and developing long-term memory skills for dynamic environments.
The challenge of long memory