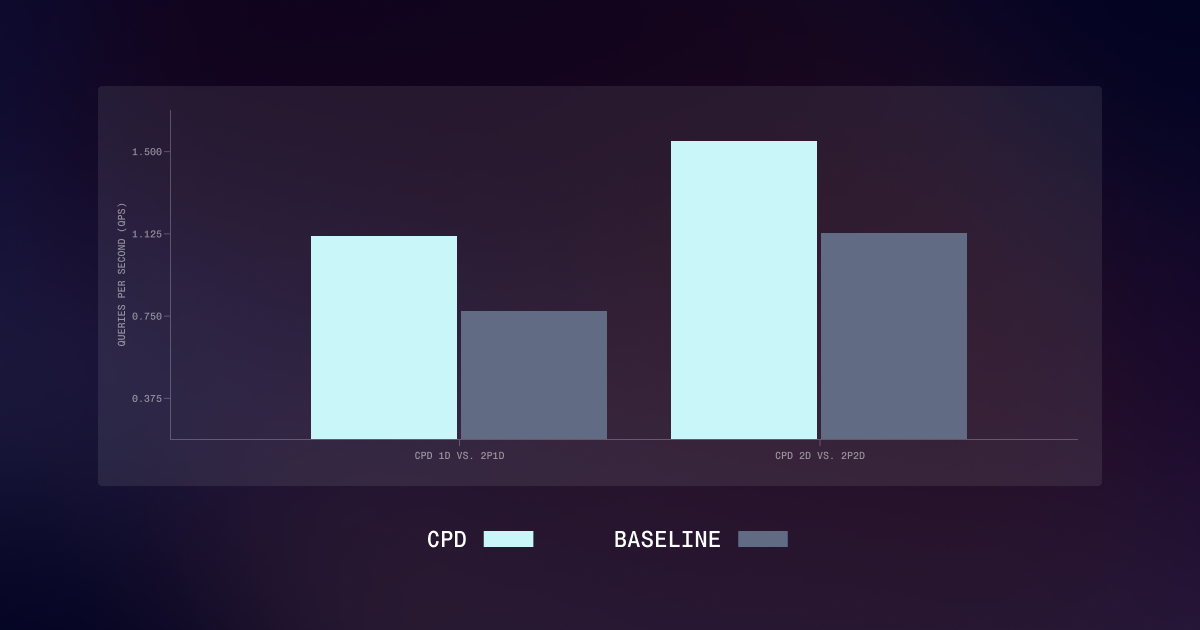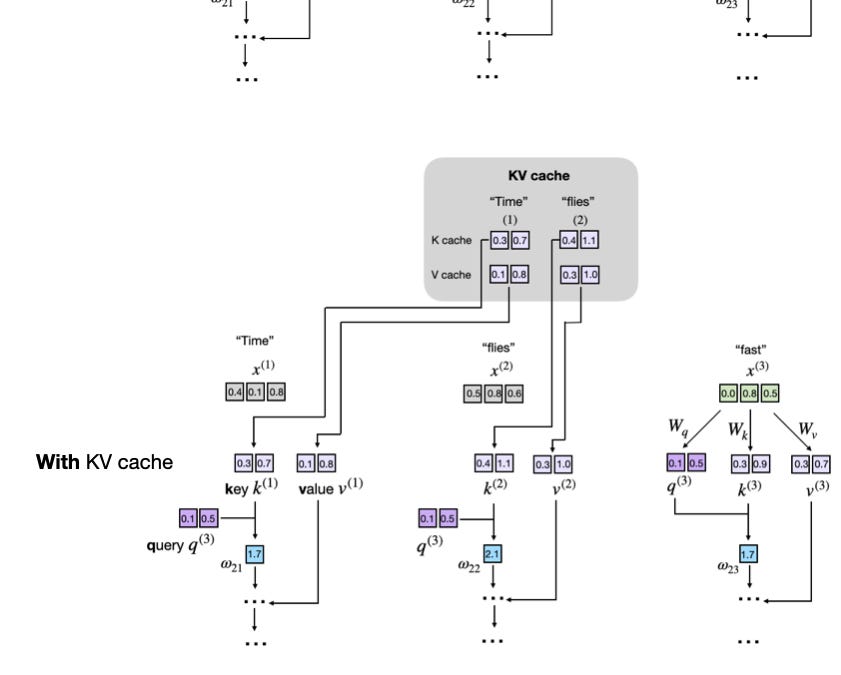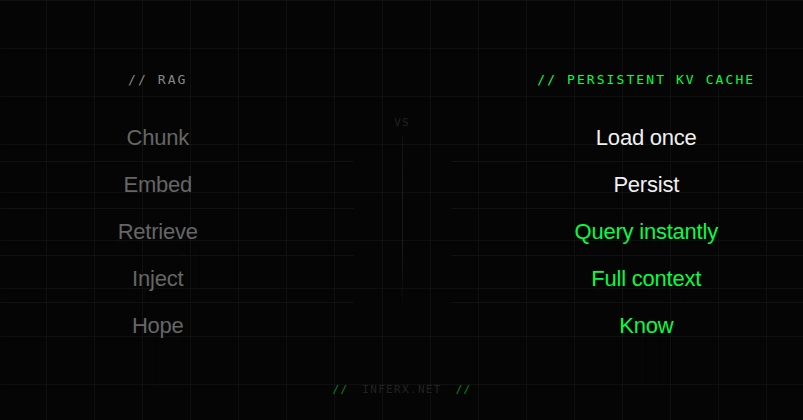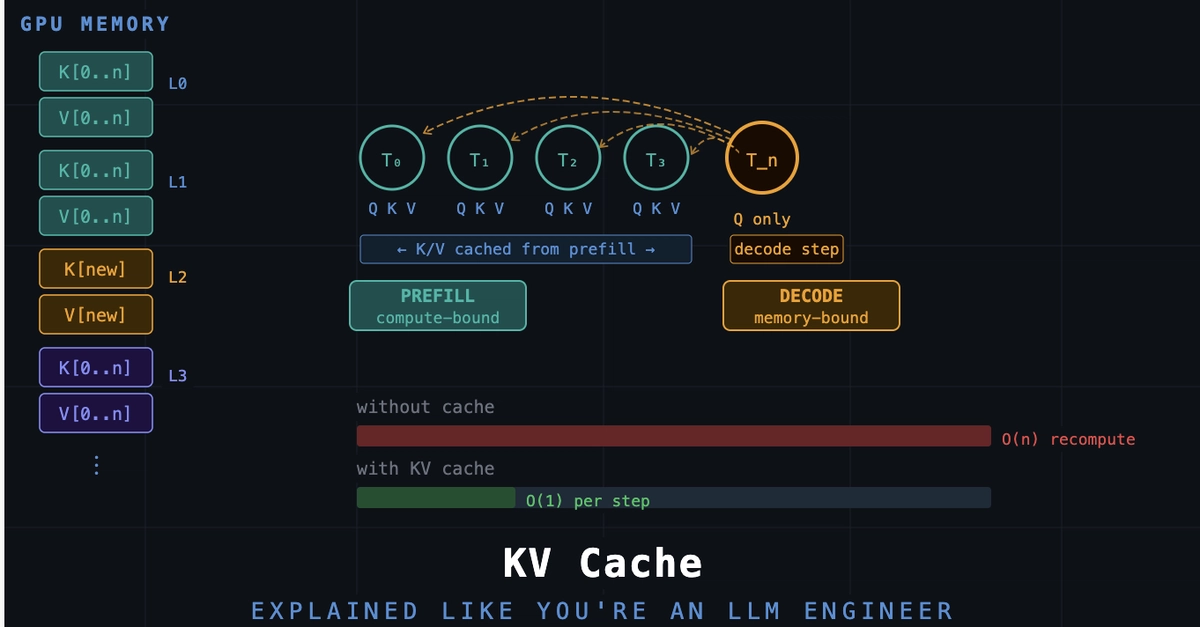
How transformer inference actually works under the hood — and why KV cache is the single most important optimization keeping your LLM from crawling.
If you've ever wondered why LLMs respond fast even on long prompts — the answer is KV cache. But most explanations stop at "it stores keys and values." This goes deeper.
What You'll Learn
By the end of this article you'll understand:
Why autoregressive LLM generation is expensive by design