The KV-cache is the single most important optimisation in LLM inference — and the reason real-time chat with a model is even feasible. Here's what it is and why it matters.
Generation is autoregressive
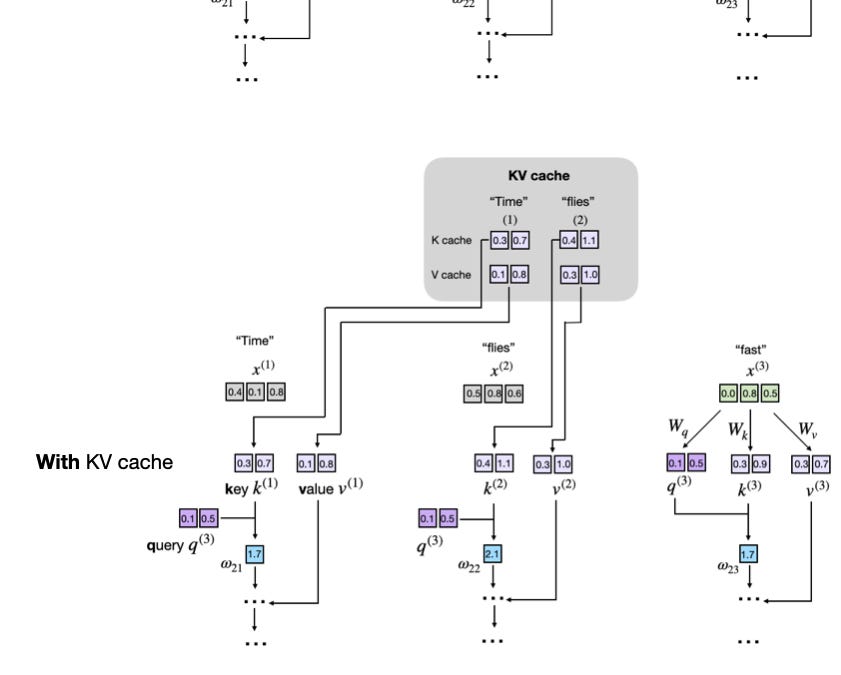
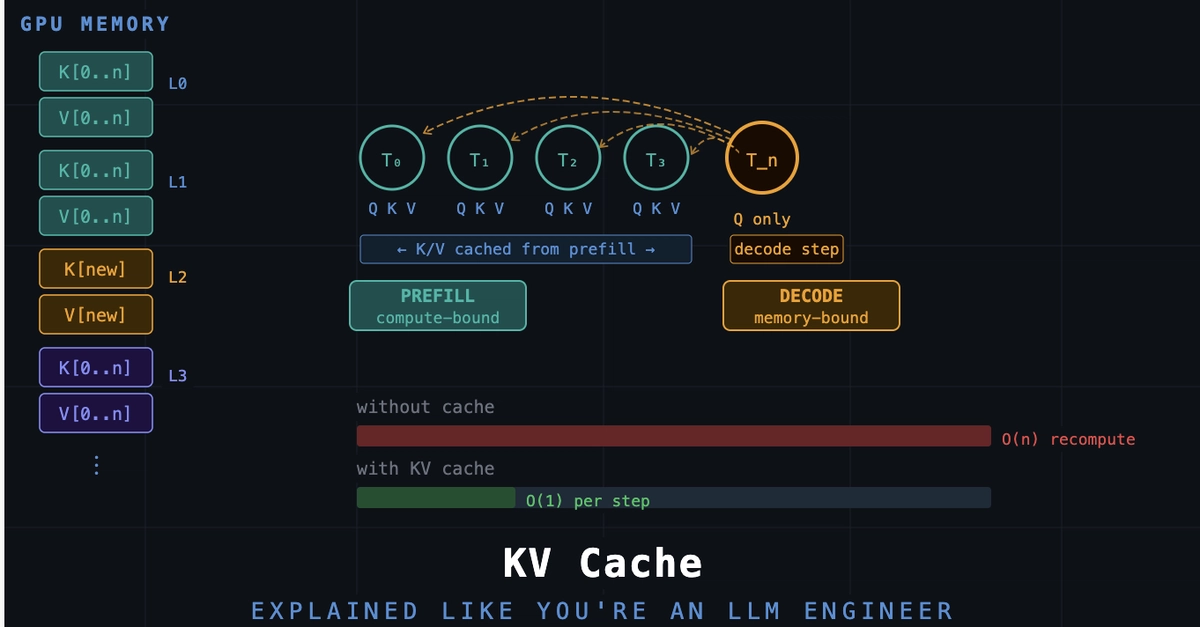
An LLM produces text one token at a time: emit a token, append it, run the whole model again for the next. Inside each attention layer, every token becomes a Query, a Key, and a Value. To produce the newest token, its Query is scored against the Keys of all previous tokens, and those weights blend their Values. So generating token t needs the K and V of tokens 1…t.
The naïve approach is quadratic
Without a cache, each step re-encodes the entire prefix to rebuild K/V for tokens 1…t. Step 1 processes 1 token, step 2 processes 2, …, step N processes N. Total work ≈ 1+2+…+N = N(N+1)/2 — quadratic. Token 1's K/V gets recomputed on every single step even though it never changes.