
LLMs generate text one token at a time.
That sounds simple.
But without KV Cache, every new token would repeat a lot of old work.
That is why inference optimization starts with keys and values.
Core Idea
LLMs generate text one token at a time. That sounds simple. But without KV Cache, every new token...
LLMs generate text one token at a time.
That sounds simple.
But without KV Cache, every new token would repeat a lot of old work.
That is why inference optimization starts with keys and values.
Core Idea
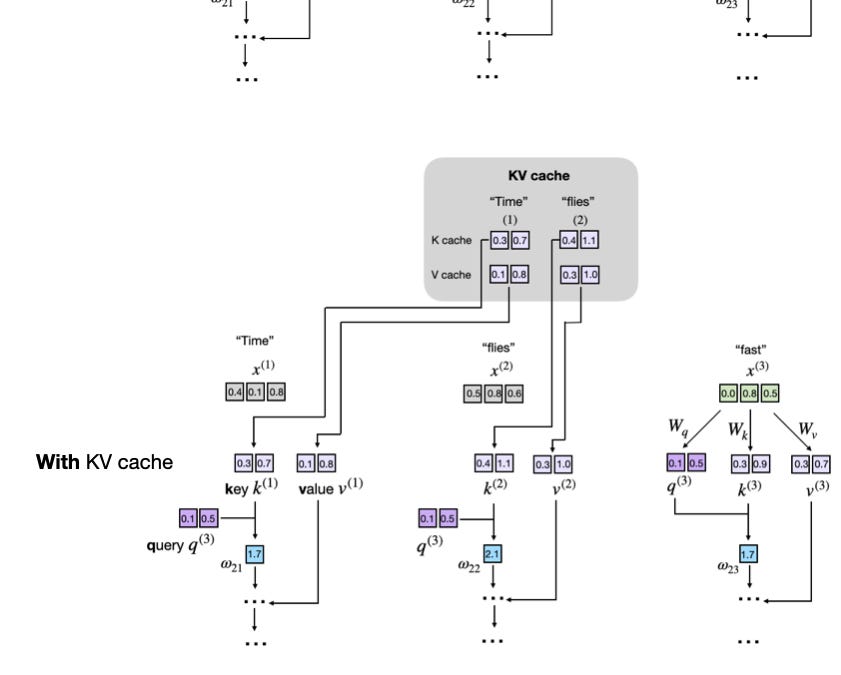
KV caches are one of the most critical techniques for efficient inference in LLMs in production.
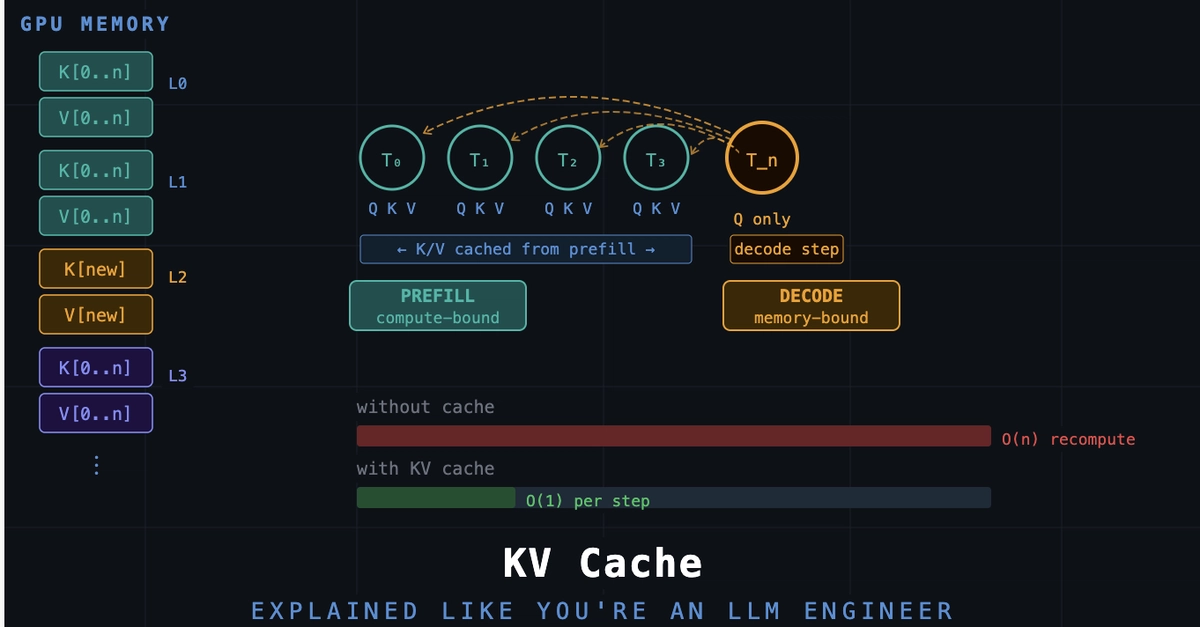
How transformer inference actually works under the hood — and why KV cache is the single most...

FP8 and INT8 KV caches cut attention state ~50%, but they shift the target model's logit distribution — and that can quietly…

An explanation of the KV cache memory problem in production LLM serving and how PagedAttention (the technique behind vLLM) solves…

LLM KV Cache Optimization, Open Model Evaluation, & Agent Engineering Skills for Local...
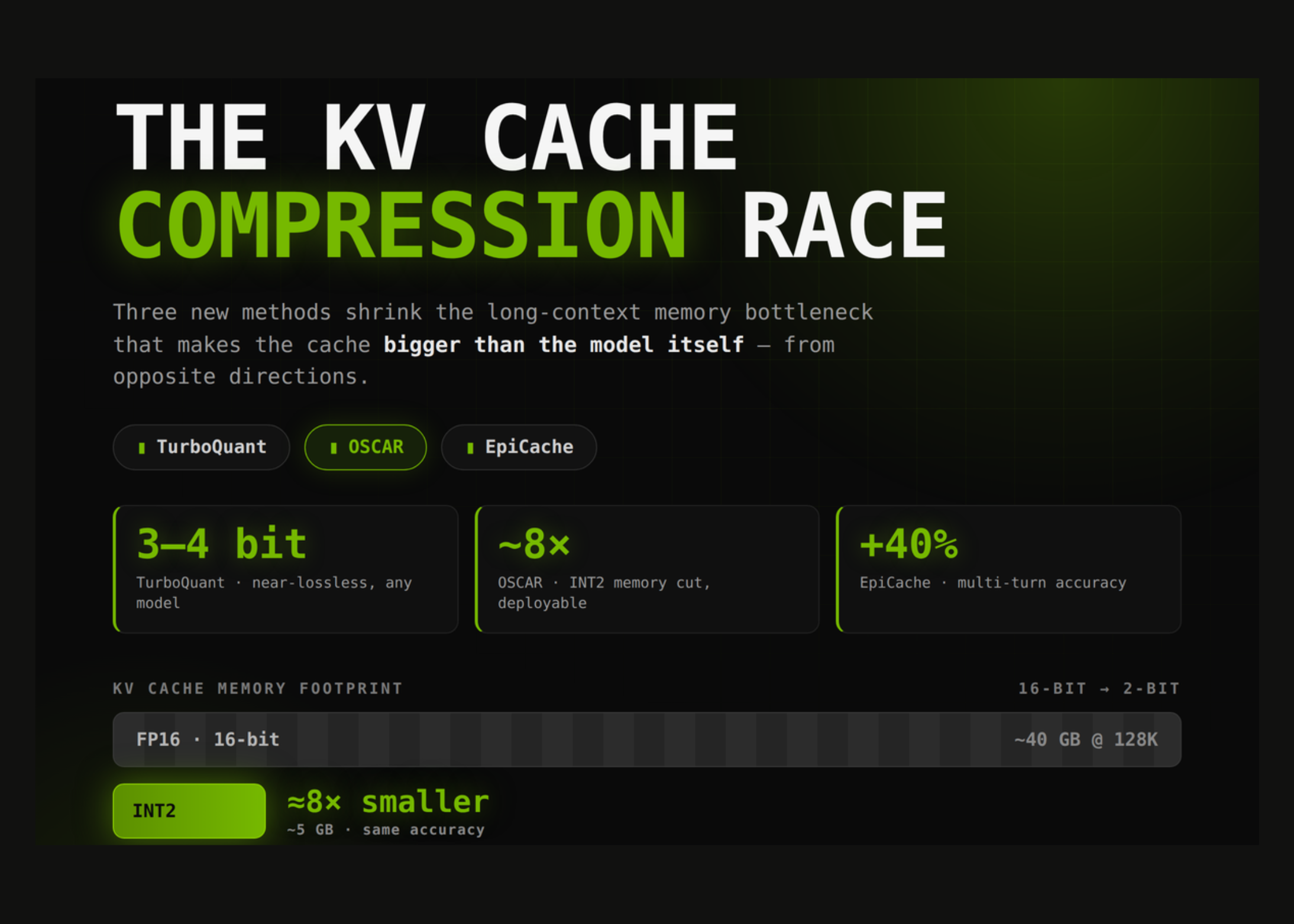
Compare TurboQuant, OSCAR, and EpiCache: three 2026 methods compressing the LLM KV cache to cut long-context memory cost
