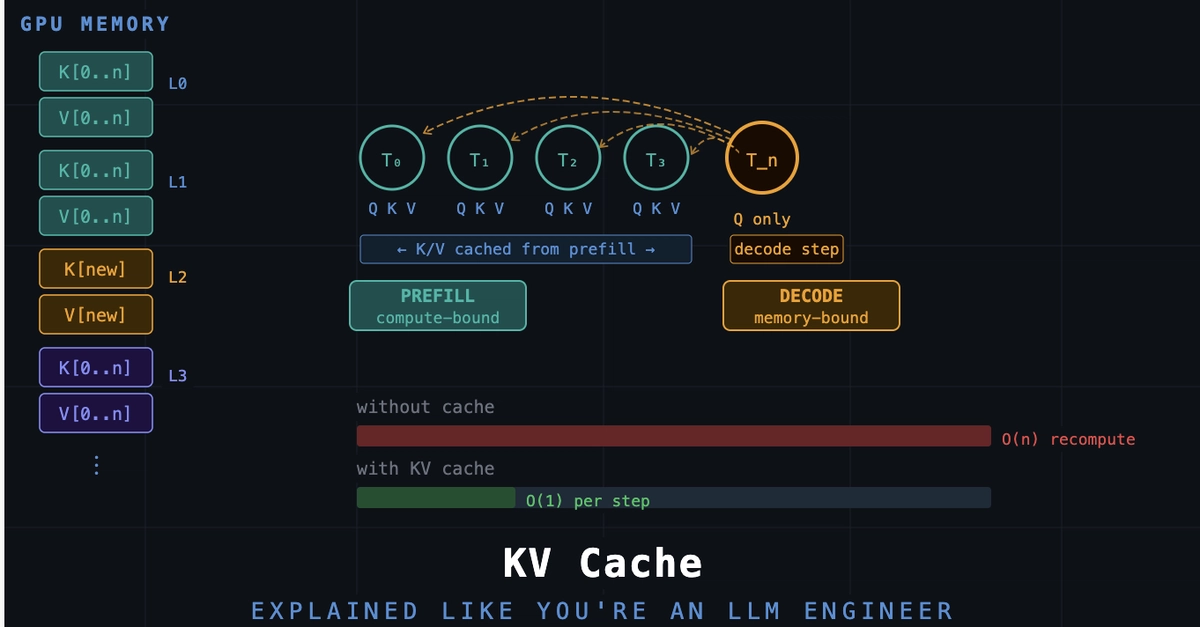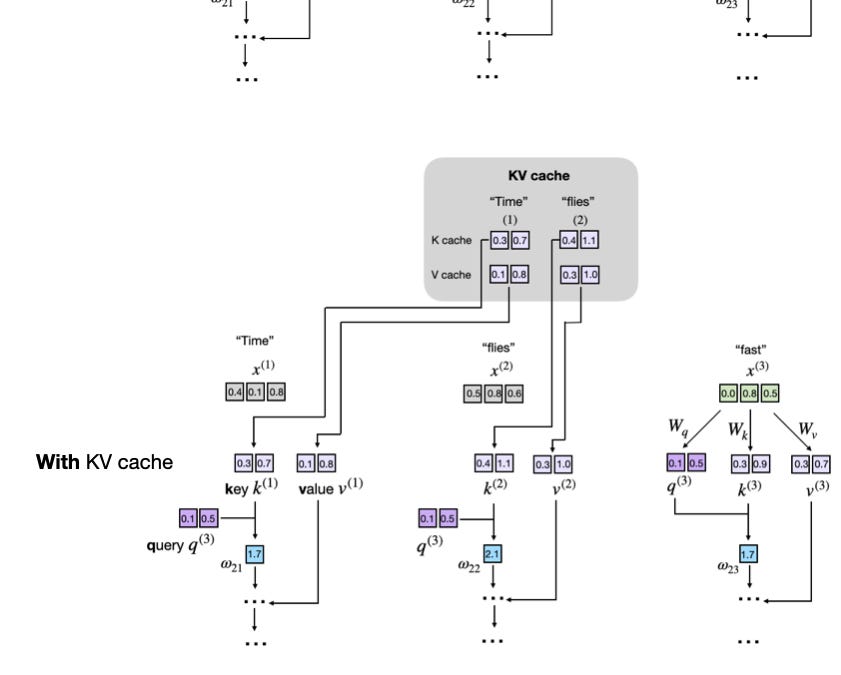
KV caches are one of the most critical techniques for efficient inference in LLMs in production. KV caches are an important component for compute-efficient LLM inference in production. This article explains how they work conceptually and in code with a from-scratch, human-readable implementation.It's been a while since I shared a technical tutorial explaining fundamental LLM concepts. As I am currently recovering from an injury and working on a bigger LLM research-focused article, I thought I'd share a tutorial article on a topic several readers asked me about (as it was not included in my Building a Large Language Model From Scratch book).Happy reading!In short, a KV cache stores intermediate key (K) and value (V) computations for reuse during inference (after training), which results in a substantial speed-up when generating text. The downside of a KV cache is that it adds more complexity to the code, increases memory requirements (the main reason I initially didn't include it in the book), and can't be used during training. However, the inference speed-ups are often well worth the trade-offs in code complexity and memory when using LLMs in production.Imagine the LLM is generating some text. Concretely, suppose the LLM is given the following prompt: "Time". As you may already know, LLMs generate one word (or token) at a time, and the two following text generation steps may look as illustrated in the figure below:The diagram illustrates how an LLM generates text one token at a time. Starting with the prompt "Time", the model generates the next token "flies." In the next step, the full sequence "Time flies" is reprocessed to generate the token "fast".Note that there is some redundancy in the generated LLM text outputs, as highlighted in the next figure:This figure highlights the repeated context ("Time flies") that must be reprocessed by the LLM at each generation step. Since the LLM does not cache intermediate key/value states, it re-encodes the full sequence every time a new token (e.g., "fast") is generated.When we implement an LLM text generation function, we typically only use the last generated token from each step. However, the visualization above highlights one of the main inefficiencies on a conceptual level. This inefficiency (or redundancy) becomes more clear if we zoom in on the attention mechanism itself. (If you are curious about attention mechanisms, you can read more in Chapter 3 of my Build a Large Language Model (From Scratch) book or my Understanding and Coding Self-Attention, Multi-Head Attention, Causal-Attention, and Cross-Attention in LLMs article).The following figure shows an excerpt of an attention mechanism computation that is at the core of an LLM. Here, the input tokens ("Time" and "flies") are encoded as 3-dimensional vectors (in reality, these vectors are much larger, but this would make it challenging to fit them into a small figure). The matrices W are the weight matrices of the attention mechanism that transform these inputs into key, value, and query vectors.The figure below shows an excerpt of the underlying attention score computation with the key and value vectors highlighted:This figure illustrates how the LLM derives key (k) and value (v) vectors from token embeddings during attention computation. Each input token (e.g., "Time" and "flies") is projected using learned matrices W_k and W_v to obtain its corresponding key and value vectors.As mentioned earlier, LLMs generate one word (or token) at a time. Suppose the LLM generated the word "fast" so that the prompt for the next round becomes "Time flies fast". This is illustrated in the next figure below:This diagram shows how the LLM recomputes key and value vectors for previously seen tokens ("Time" and "flies") during each generation step. When generating the third token ("fast"), the model recomputes the same k(1)/v(1) and k(2)/v(2) vectors again, rather than reusing them. This repeated computation highlights the inefficiency of not using a KV cache during autoregressive decoding.As we can see, based on comparing the previous 2 figures, the keys and value vectors for the first two tokens are exactly the same, and it would be wasteful to recompute them in each next-token text generation round.Now, the idea of the KV cache is to implement a caching mechanism that stores the previously generated key and value vectors for reuse, which helps us to avoid these unnecessary recomputations.After we went over the basic concept in the previous section, let's go into a bit more detail before we look at a concrete code implementation. If we have a text generation process without KV cache for "Time flies fast", we can think of it as follows:Notice the redundancy: tokens "Time" and "flies" are recomputed at every new generation step. The KV cache resolves this inefficiency by storing and reusing previously computed key and value vectors:Initially, the model computes and caches key and value vectors for the input tokens.For each new token generated, the model only computes key and value vectors for that specific token.Previously computed vectors are retrieved from the cache to avoid redundant computations.The table below summarizes the computation and caching steps and states:The benefits here are that "Time" is computed once and reused twice, and "flies" is computed once and reused once. (It's a short text example for simplicity, but it should be intuitive to see that the longer the text, the more we get to reuse already computed keys and values, which increases the generation speed.)n speed.)The following figure illustrates generation step 3 with and without a KV cache side by side.Comparing text generation with and without a KV cache. In the top panel (without cache), key and value vectors are recomputed for each token step, which results in redundant operations. In the bottom panel (with cache), previously computed keys and values are retrieved from the KV cache to avoid recomputation for faster generation.So, if we want to implement a KV cache in code, all we have to do is compute the keys and values as usual but then store them so that we can retrieve them in the next round. The next section illustrates this with a concrete code example.There are many ways to implement a KV cache, with the main idea being that we only compute the key and value tensors for the newly generated tokens in each generation step.I opted for a simple one that emphasizes code readability. I think it's easiest to just scroll through the code changes to see how it's implemented.There are two files I shared on GitHub, which are self-contained Python scripts that implement an LLM with and without KV cache from scratch:gpt_ch04.py: Self-contained code taken from Chapters 3 and 4 of my Build a Large Language Model (From Scratch) book to implement the LLM and run the simple text generation functiongpt_with_kv_cache.py: The same as above, but with the necessary changes made to implement the KV cache.To read through the KV cache-relevant code modifications, you can either:a. Open the gpt_with_kv_cache.py file and look out for the # NEW sections that mark the new changes:b. Check out the two code files via a file diff tool of your choice to compare the changes:In additoin, to summarize the implementation details, there's a short walkthrough in the following subsections.Inside the MultiHeadAttention constructor, we add two buffers, cache_k and cache_v, which will hold concatenated keys and values across steps:self.register_buffer("cache_k", None)
Understanding and Coding the KV Cache in LLMs from Scratch
KV caches are one of the most critical techniques for efficient inference in LLMs in production.
2,877 words~13 min read