
Recent Developments in LLM Architectures: KV Sharing, mHC, and Compressed…
From Gemma 4 to DeepSeek V4, How New Open-Weight LLMs Are Reducing Long-Context Costs
23articoli totali nell'archivio
From Gemma 4 to DeepSeek V4, How New Open-Weight LLMs Are Reducing Long-Context Costs
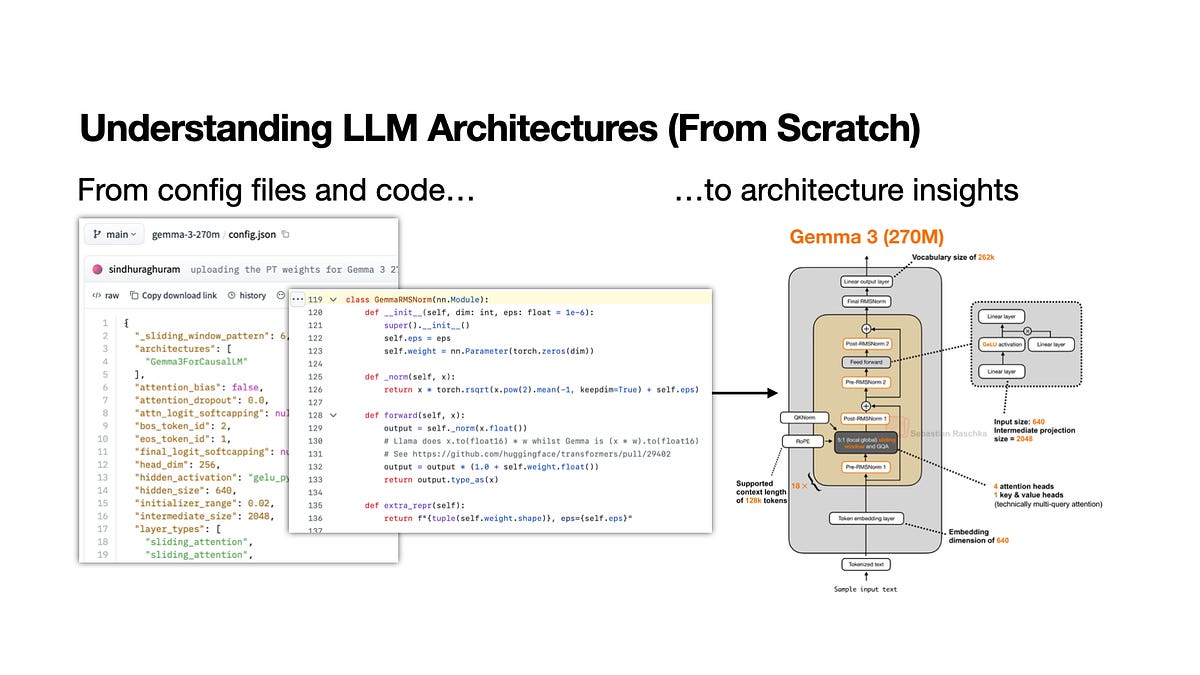
A learning-oriented workflow for understanding new open-weight model releases
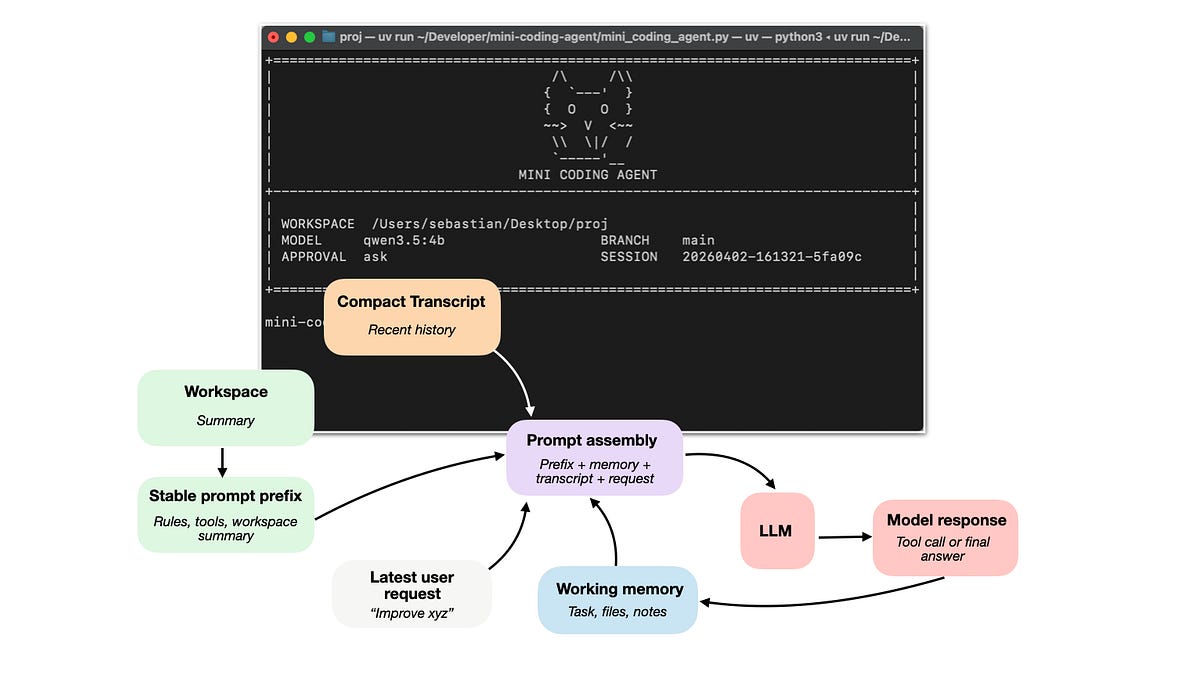
How coding agents use tools, memory, and repo context to make LLMs work better in practice

From MHA and GQA to MLA, sparse attention, and hybrid architectures
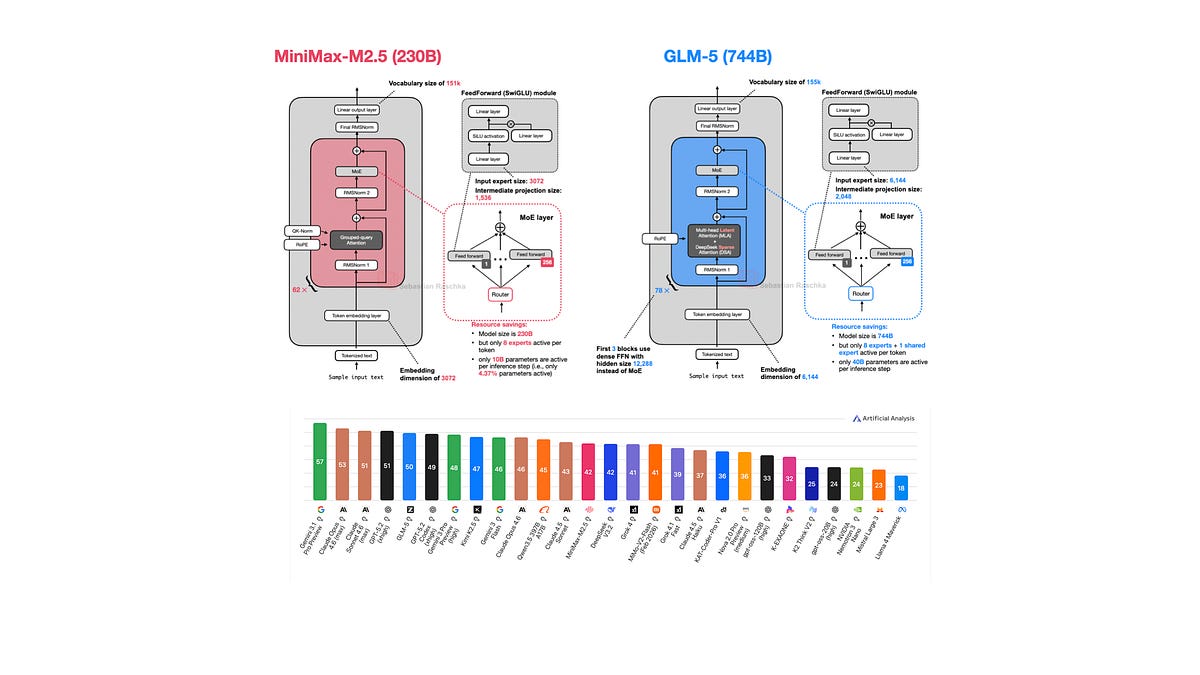
A Round Up And Comparison of 10 Open-Weight LLM Releases in Spring 2026
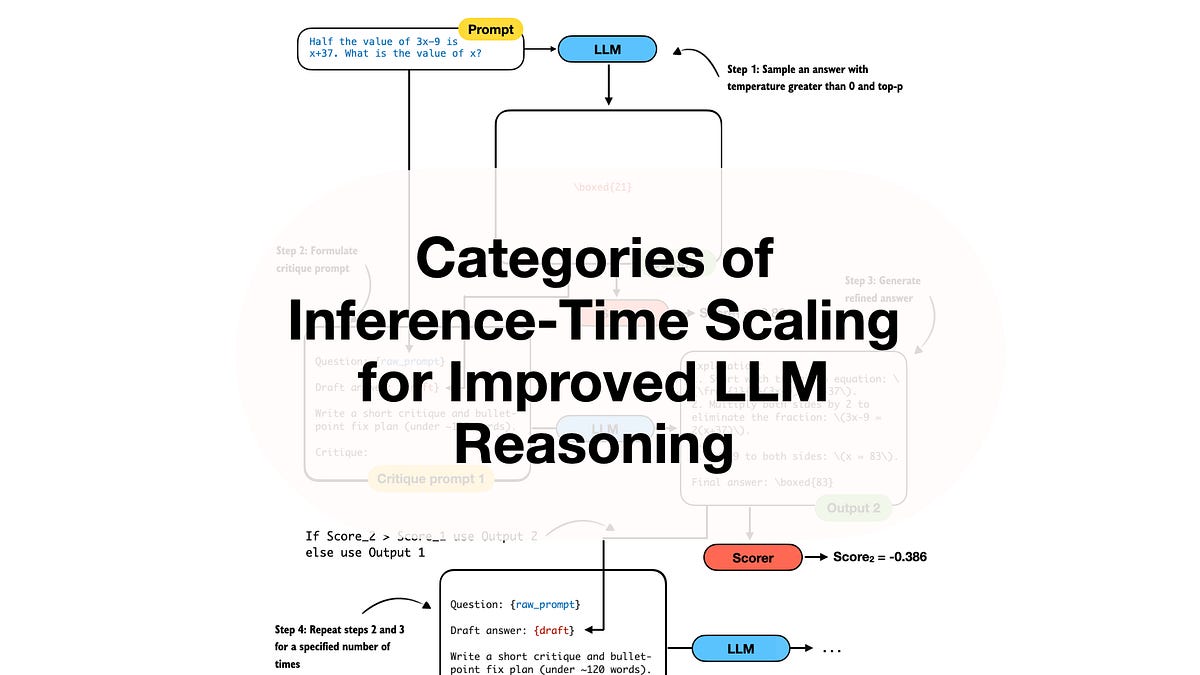
And an Overview of Recent Inference-Scaling Papers
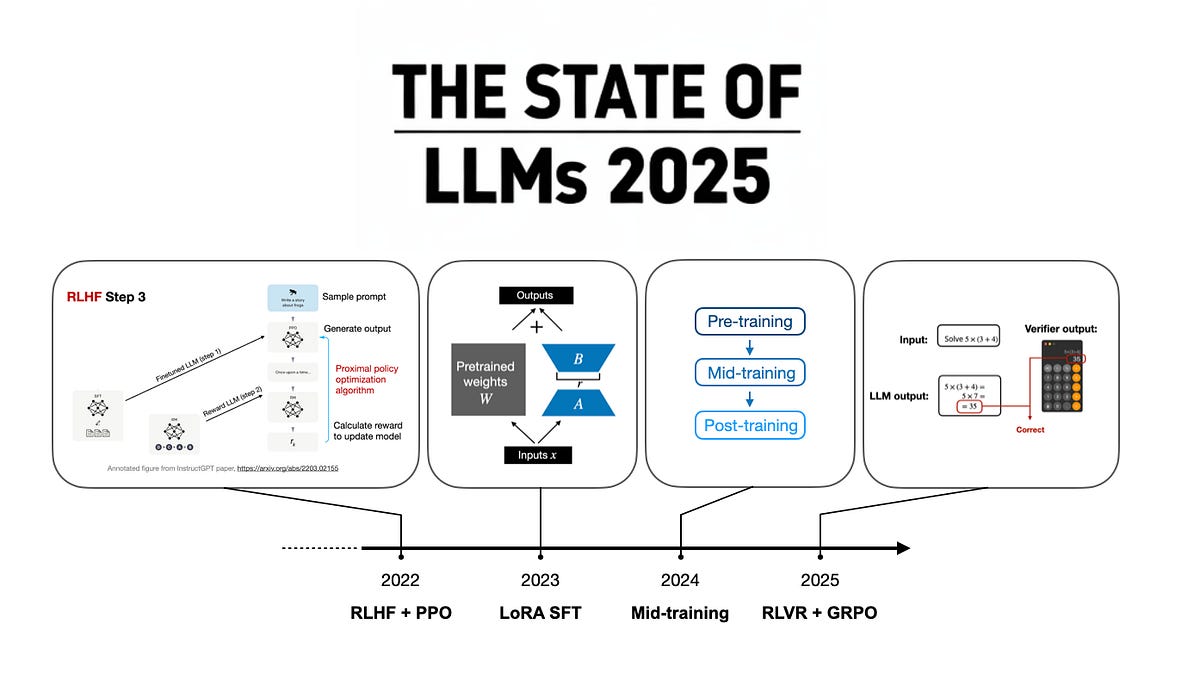
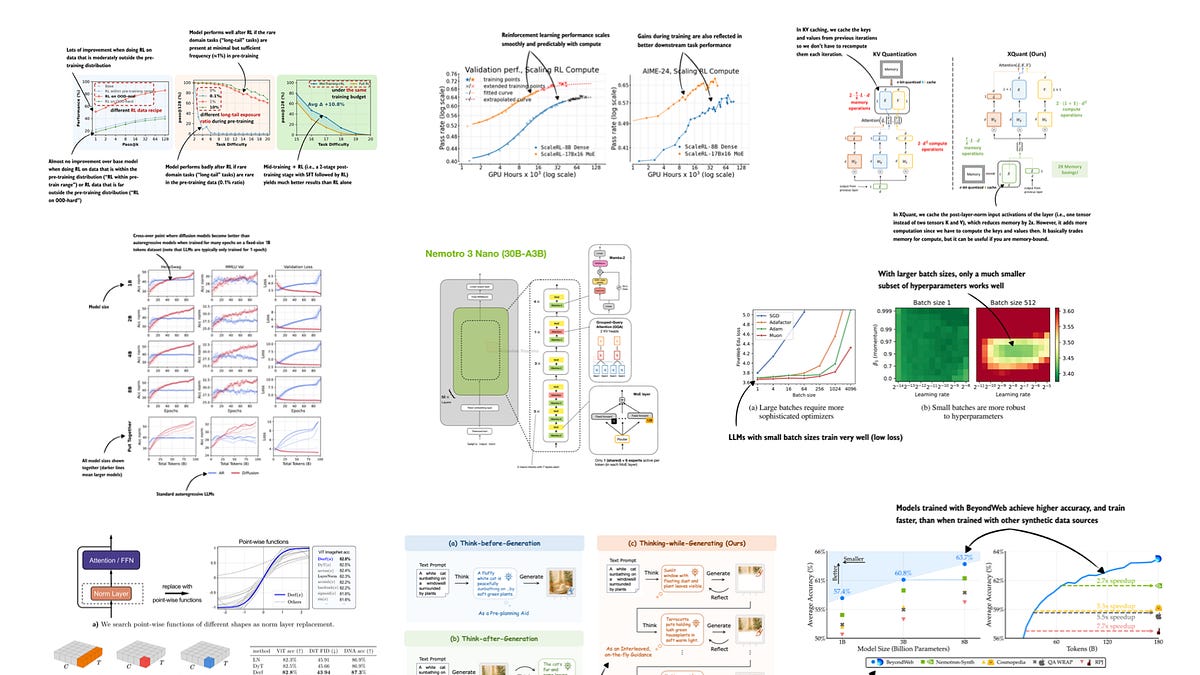
A 2025 review of large language models, from DeepSeek R1 and RLVR to inference-time scaling, benchmarks, architectures, and…
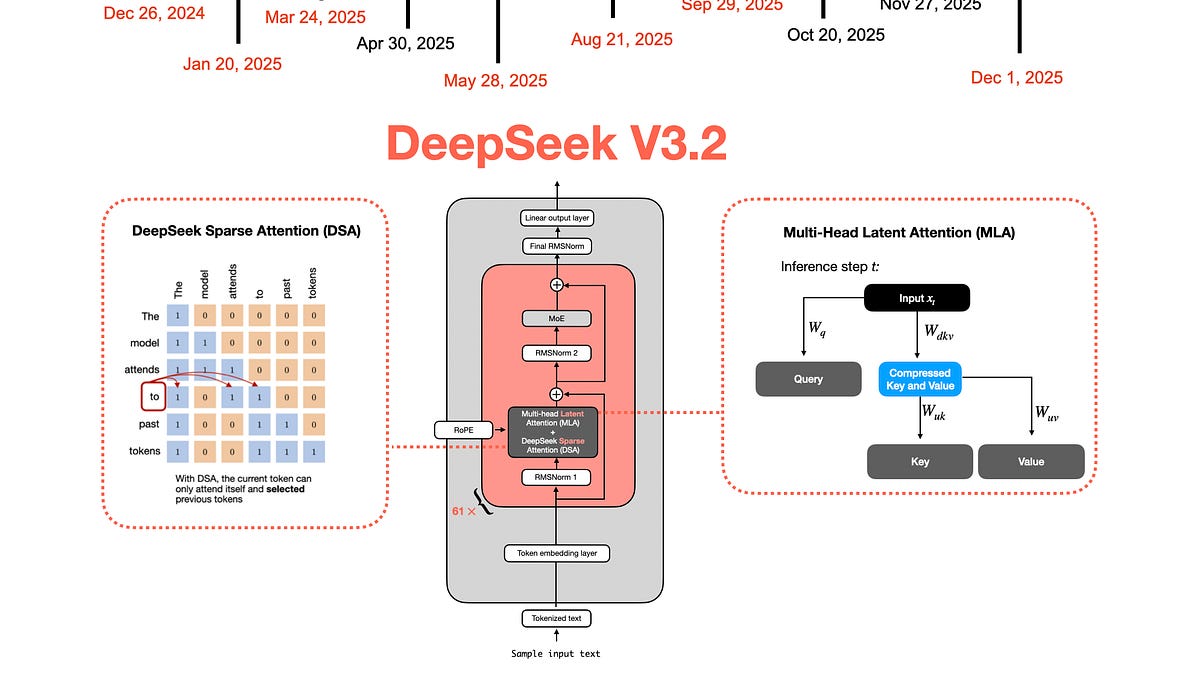
Understanding How DeepSeek's Flagship Open-Weight Models Evolved
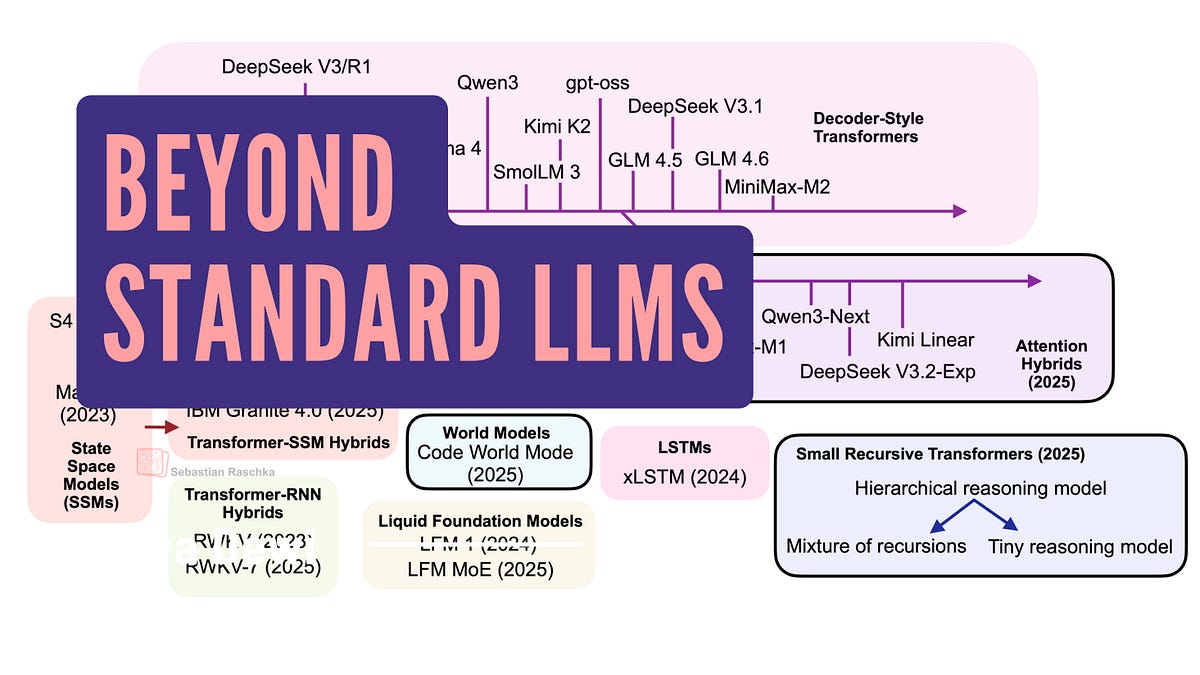
Linear Attention Hybrids, Text Diffusion, Code World Models, and Small Recursive Transformers
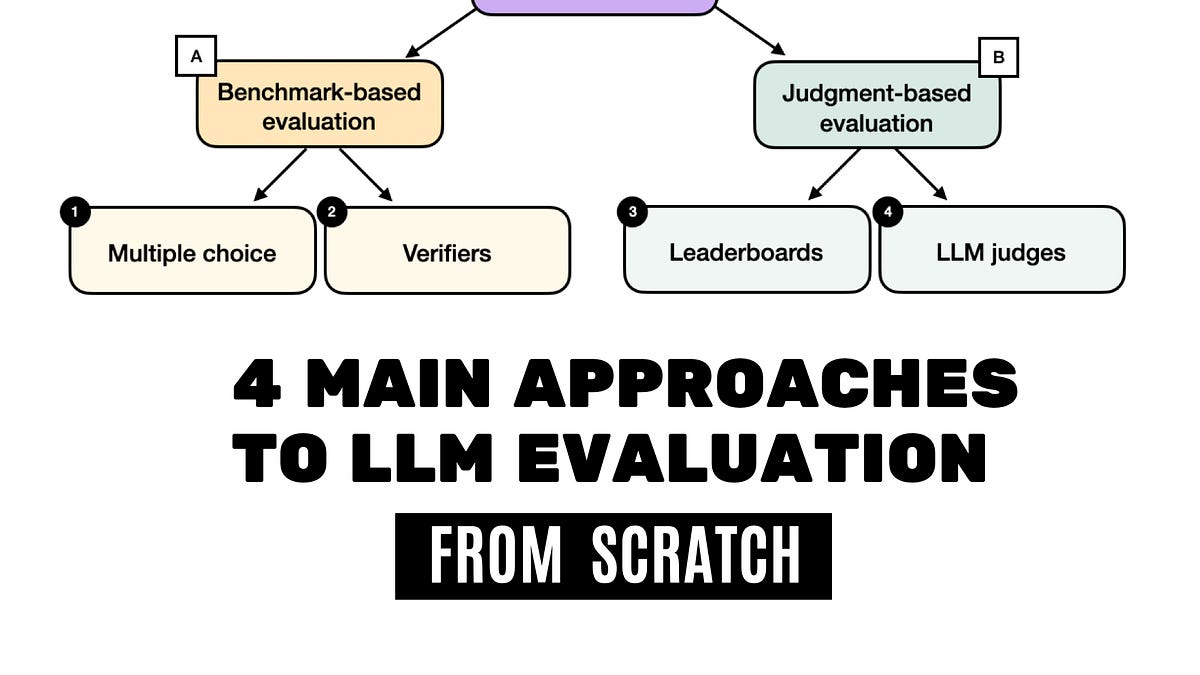
Multiple-Choice Benchmarks, Verifiers, Leaderboards, and LLM Judges with Code Examples
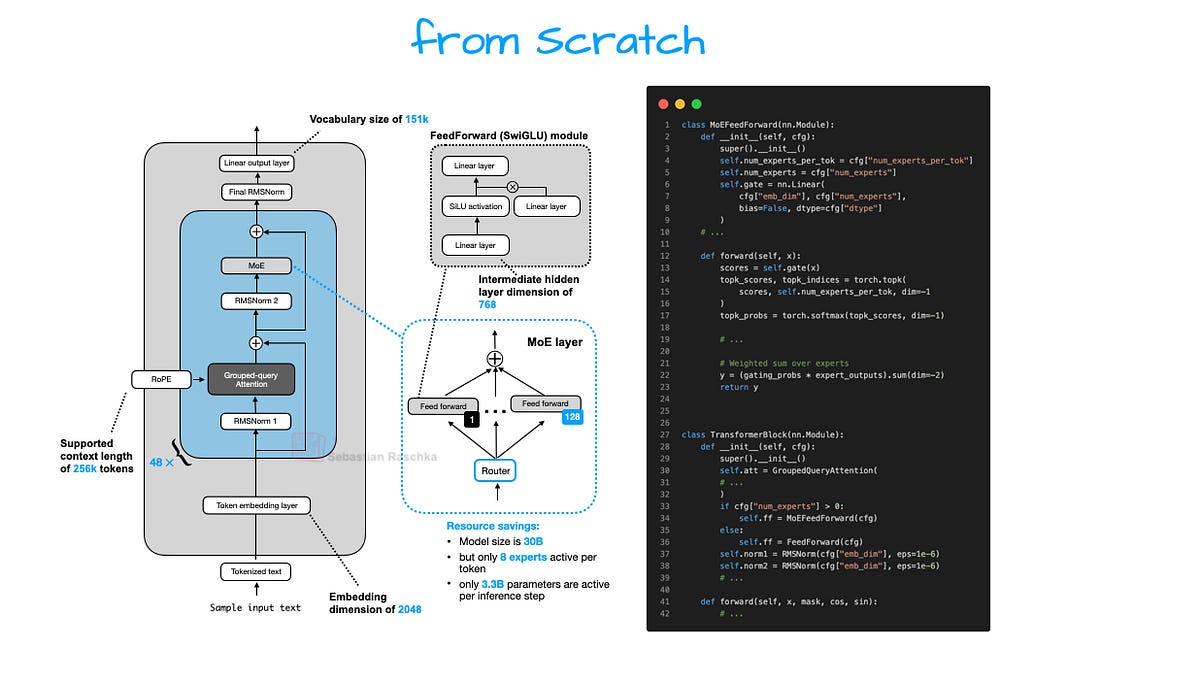
A Detailed Look at One of the Leading Open-Source LLMs
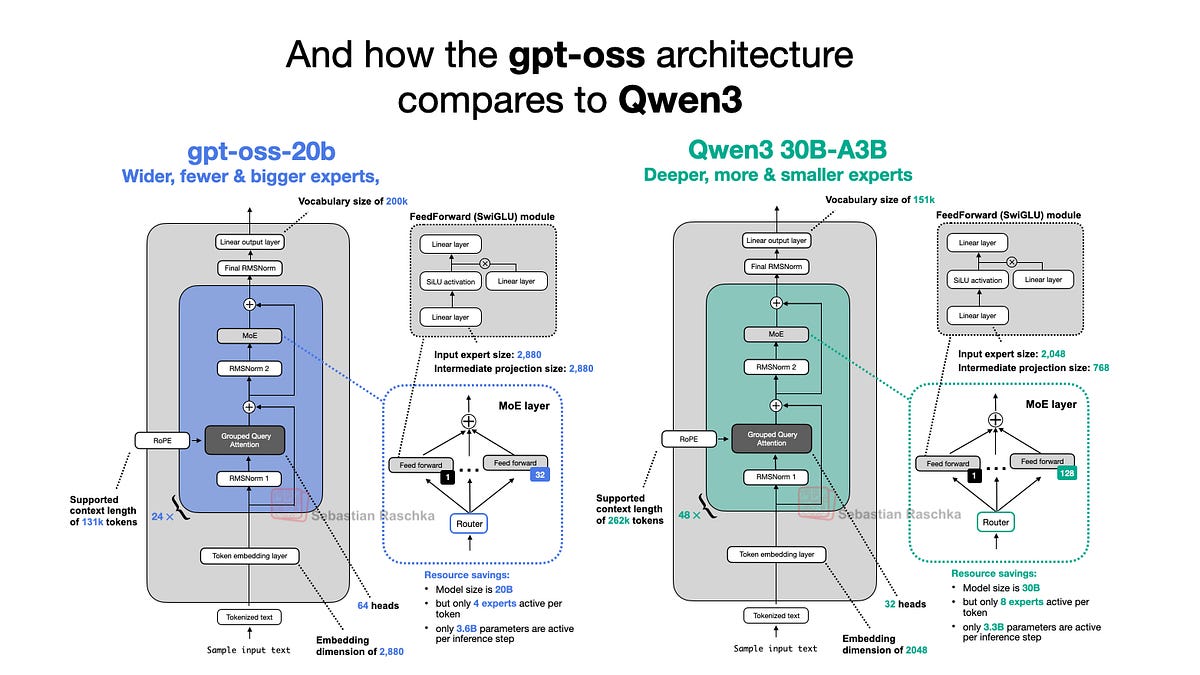
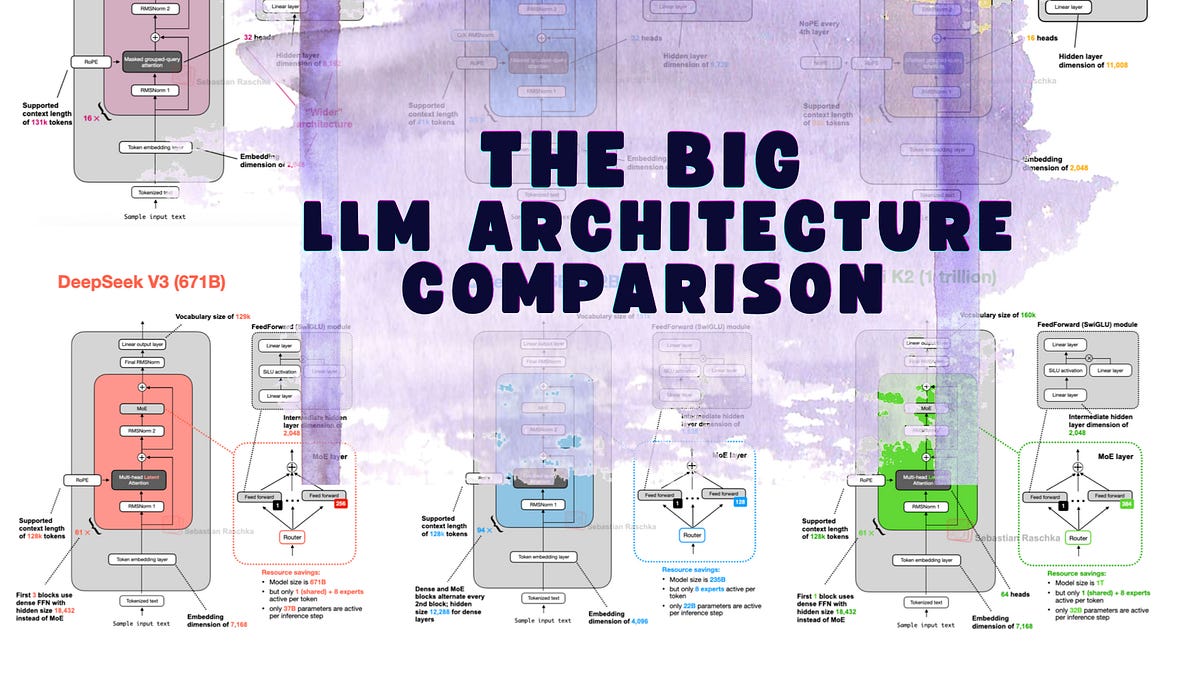
From DeepSeek-V3 to Kimi K2: A Look At Modern LLM Architecture Design
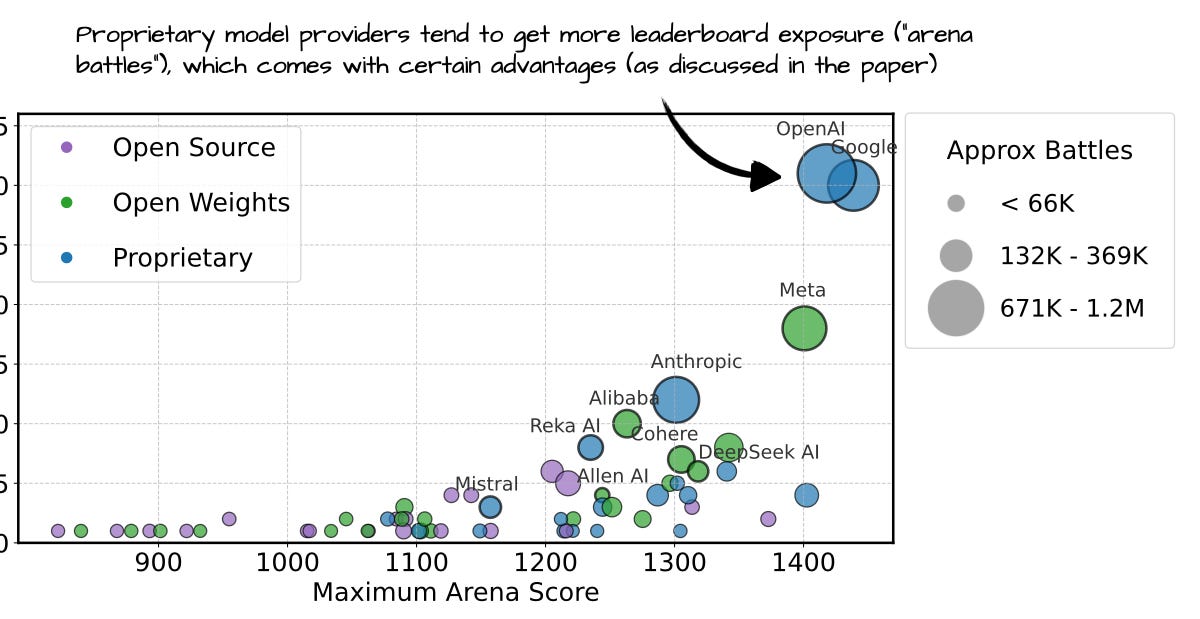
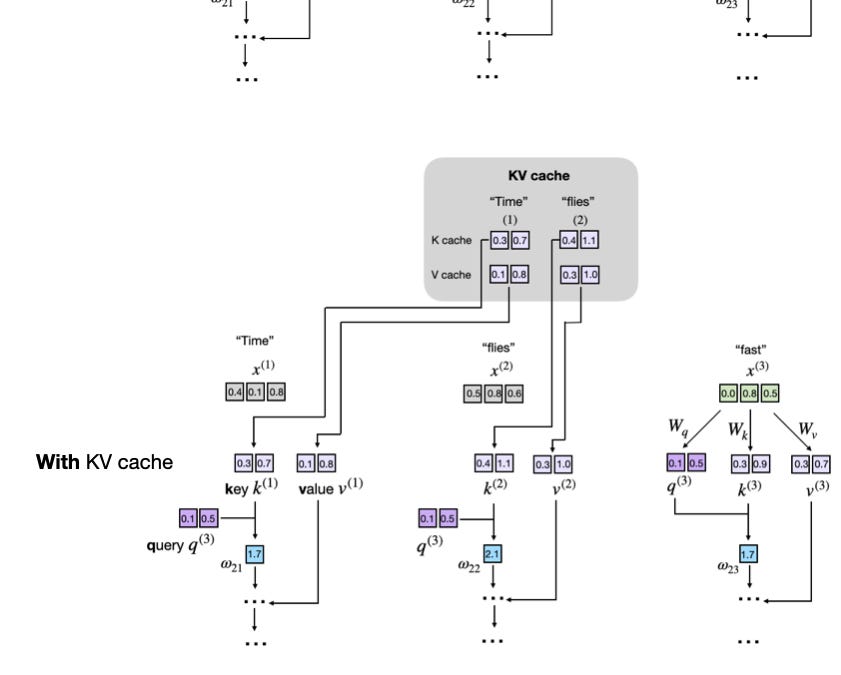
KV caches are one of the most critical techniques for efficient inference in LLMs in production.