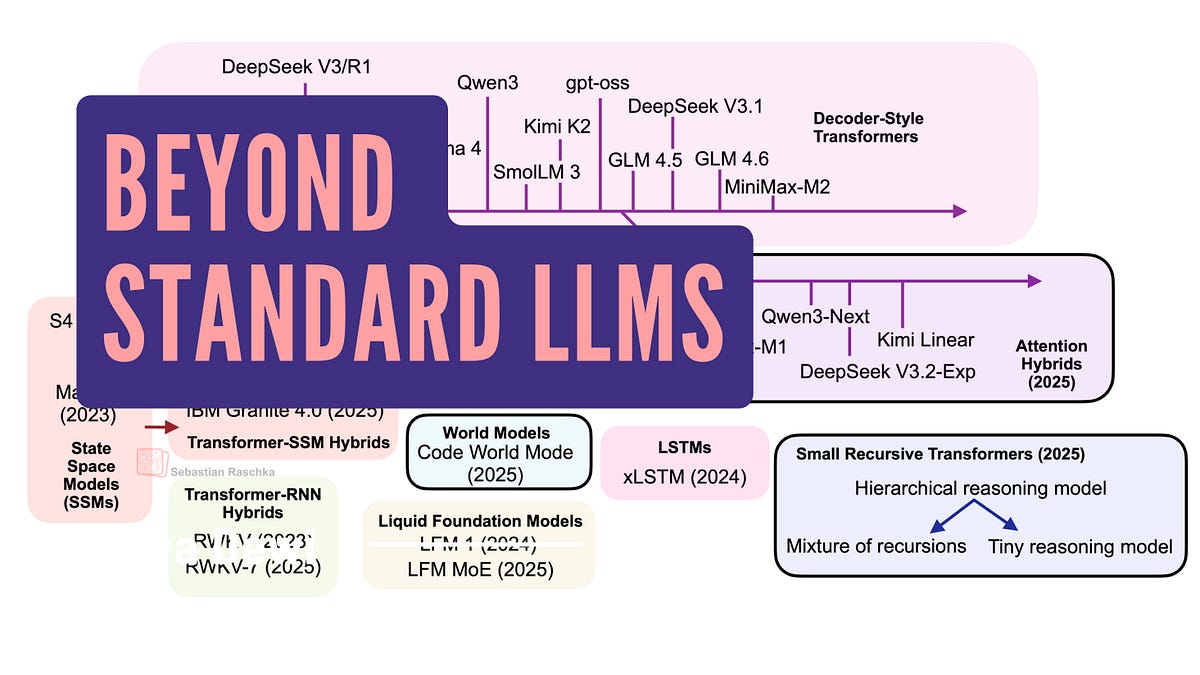
From DeepSeek R1 to MiniMax-M2, the largest and most capable open-weight LLMs today remain autoregressive decoder-style transformers, which are built on flavors of the original multi-head attention mechanism.However, we have also seen alternatives to standard LLMs popping up in recent years, from text diffusion models to the most recent linear attention hybrid architectures. Some of them are geared towards better efficiency, and others, like code world models, aim to improve modeling performance.After I shared my Big LLM Architecture Comparison a few months ago, which focused on the main transformer-based LLMs, I received a lot of questions with respect to what I think about alternative approaches. (I also recently gave a short talk about that at the PyTorch Conference 2025, where I also promised attendees to follow up with a write-up of these alternative approaches). So here it is!Figure 1: Overview of the LLM landscape. This article covers those architectures surrounded by the black frames. The decoder-style transformers are covered in my “The Big Architecture Comparison” article. Other non-framed architectures may be covered in future articles.Note that ideally each of these topics shown in the figure above would deserve at least a whole article itself (and hopefully get it in the future). So, to keep this article at a reasonable length, many sections are reasonably short. However, I hope this article is still useful as an introduction to all the interesting LLM alternatives that emerged in recent years.PS: The aforementioned PyTorch conference talk will be uploaded to the official PyTorch YouTube channel. In the meantime, if you are curious, you can find a practice recording version below.(There is also a YouTube version here.)Transformer-based LLMs based on the classic Attention Is All You Need architecture are still state-of-the-art across text and code. If we just consider some of the highlights from late 2024 to today, notable models includeDeepSeek V3/R1OLMo 2Gemma 3Mistral Small 3.1Llama 4Qwen3SmolLM3Kimi K2gpt-ossGLM-4.5GLM-4.6MiniMax-M2and many more.(The list above focuses on the open-weight models; there are proprietary models like GPT-5, Grok 4, Gemini 2.5, etc. that also fall into this category.)Figure 2: An overview of the most notable decoder-style transformers released in the past year.Since I talked and wrote about transformer-based LLMs so many times, I assume you are familiar with the broad idea and architecture. If you’d like a deeper coverage, I compared the architectures listed above (and shown in the figure below) in my The Big LLM Architecture Comparison article.(Side note: I could have grouped Qwen3-Next and Kimi Linear with the other transformer-state space model (SSM) hybrids in the overview figure. Personally, I see these other transformer-SSM hybrids as SSMs with transformer components, whereas I see the models discussed here (Qwen3-Next and Kimi Linear) as transformers with SSM components. However, since I have listed IBM Granite 4.0 and NVIDIA Nemotron Nano 2 in the transformer-SSM box, an argument could be made for putting them into a single category.)Figure 3. A subset of the architectures discussed in my The Big Architecture Comparison (https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison) article.If you are working with or on LLMs, for example, building applications, fine-tuning models, or trying new algorithms, I would make these models my go-to. They are tested, proven, and perform well.Moreover, as discussed in the The Big Architecture Comparison article, there are many efficiency improvements, including grouped-query attention, sliding-window attention, multi-head latent attention, and others.However, it would be boring (and shortsighted) if researchers and engineers didn’t work on trying alternatives. So, the remaining sections will cover some of the interesting alternatives that emerged in recent years.Before we discuss the “more different” approaches, let’s first look at transformer-based LLMs that have adopted more efficient attention mechanisms. In particular, the focus is on those that scale linearly rather than quadratically with the number of input tokens.There’s recently been a revival in linear attention mechanisms to improve the efficiency of LLMs.The attention mechanism introduced in the Attention Is All You Need paper (2017), aka scaled-dot-product attention, remains the most popular attention variant in today’s LLMs. Besides traditional multi-head attention, it’s also used in the more efficient flavors like grouped-query attention, sliding window attention, and multi-head latent attention as discussed in my talk.The original attention mechanism scales quadratically with the sequence length:\(\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d}}\right)V\)This is because the query (Q), key (K), and value (V) are n-by-d matrices, where d is the embedding dimension (a hyperparameter) and n is the sequence length (i.e., the number of tokens).(You can find more details in my Understanding and Coding Self-Attention, Multi-Head Attention, Causal-Attention, and Cross-Attention in LLMs article)Figure 4: Illustration of the traditional scaled-dot-product attention mechanism in multi-head attention; the quadratic cost in attention due to sequence length n.Linear attention variants have been around for a long time, and I remember seeing tons of papers in the 2020s. For example, one of the earliest I recall is the 2020 Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention paper, where the researchers approximated the attention mechanism:\(\text{Attention}(Q, K, V) = \text{softmax}\!\left(\frac{QK^\top}{\sqrt{d}}\right)V \approx \phi(Q)\big(\phi(K)^\top V\big)\)Here, ϕ(⋅) is a kernel feature function, set to ϕ(x) = elu(x)+1.This approximation is efficient because it avoids explicitly computing the n×n attention matrix QKT.I don’t want to dwell too long on these older attempts. But the bottom line was that they reduced both time and memory complexity from O(n2) to O(n) to make attention much more efficient for long sequences.However, they never really gained traction as they degraded the model accuracy, and I have never really seen one of these variants applied in an open-weight state-of-the-art LLM.In the second half of this year, there has been revival of linear attention variants, as well as a bit of a back-and-forth from some model developers as illustrated in the figure below.Figure 5: An overview of the linear attention hybrid architectures.The first notable model was MiniMax-M1 with lightning attention.MiniMax-M1 is a 456B parameter mixture-of-experts (MoE) model with 46B active parameters, which came out back in June.Then, in August, the Qwen3 team followed up with Qwen3-Next, which I discussed in more detail above. Then, in September, the DeepSeek Team announced DeepSeek V3.2. (DeepSeek V3.2 sparse attention mechanism is not strictly linear but at least subquadratic in terms of computational costs, so I think it’s fair to put it into the same category as MiniMax-M1, Qwen3-Next, and Kimi Linear.)All three models (MiniMax-M1, Qwen3-Next, DeepSeek V3.2) replace the traditional quadratic attention variants in most or all of their layers with efficient linear variants.Interestingly, there was a recent plot twist, where the MiniMax team released their new 230B parameter M2 model without linear attention, going back to regular attention. The team stated that linear attention is tricky in production LLMs. It seemed to work fine with regular prompts, but it had poor accuracy in reasoning and multi-turn tasks, which are not only important for regular chat sessions but also agentic applications.This could have been a turning point where linear attention may not be worth pursuing after all. However, it gets more interesting. In October, the Kimi team released their new Kimi Linear model with linear attention.For this linear attention aspect, both Qwen3-Next and Kimi Linear adopt a Gated DeltaNet, which I wanted to discuss in the next few sections as one example of a hybrid attention architecture.Let’s start with Qwen3-Next, which replaced the regular attention mechanism by a Gated DeltaNet + Gated Attention hybrid, which helps enable the native 262k token context length in terms of memory usage (the previous 235B-A22B model model supported 32k natively, and 131k with YaRN scaling.)Their hybrid mechanism mixes Gated DeltaNet blocks with Gated Attention blocks within a 3:1 ratio as shown in the figure below.Figure 6: Qwen3-Next with gated attention and Gated DeltaNet.As depicted in the figure above, the attention mechanism is either implemented as gated attention or Gated DeltaNet. This simply means the 48 transformer blocks (layers) in this architecture alternate between this. Specifically, as mentioned earlier, they alternate in a 3:1 ratio. For instance, the transformer blocks are as follows:──────────────────────────────────
Beyond Standard LLMs
Linear Attention Hybrids, Text Diffusion, Code World Models, and Small Recursive Transformers
6,979 words~32 min read





