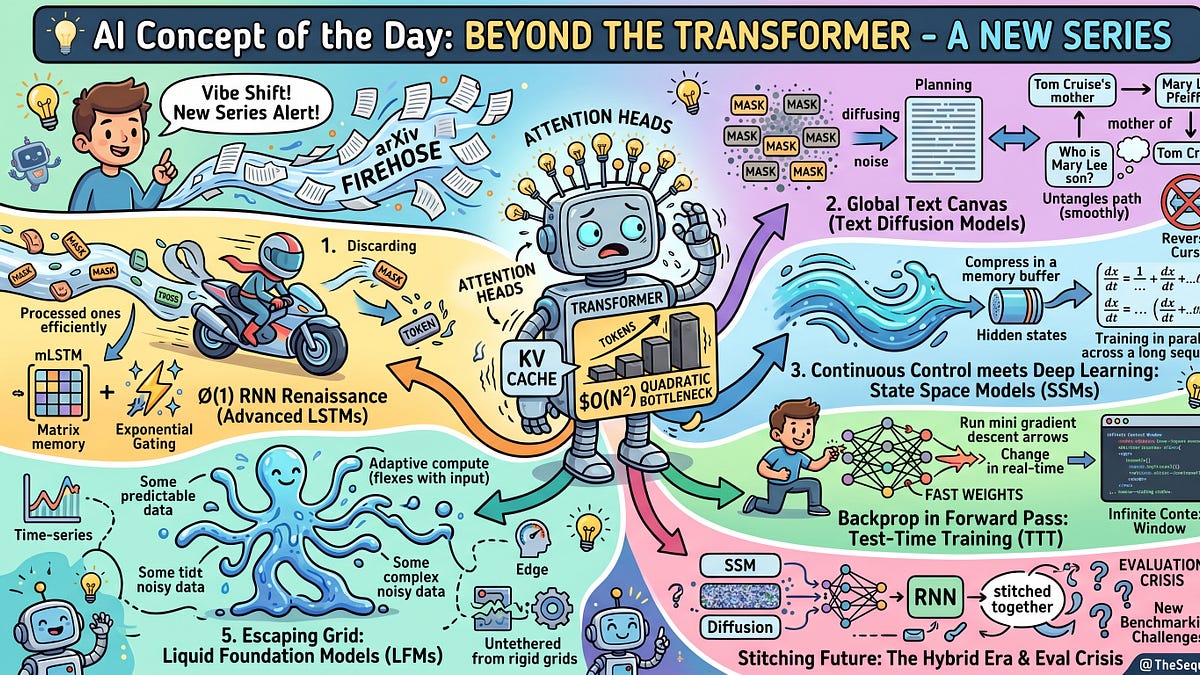
If you were training sequence models circa 2015, your entire mental model of the world was shaped by the Long Short-Term Memory (LSTM) network. Invented in the 1990s by Sepp Hochreiter and Jürgen Schmidhuber, the LSTM was the undisputed workhorse of deep learning. It translated our text, recognized our speech, and powered the first generation of Large Language Models.Then came 2017. “Attention Is All You Need” dropped, and the entire AI ecosystem pivoted. We traded the deep, architectural elegance of the LSTM for the brute-force, highly parallelizable matrix multiplications of the Transformer. The Transformer won the hardware lottery because it allowed us to map the entire sequence onto a GPU grid and train it all at once.
The Sequence Knowledge #854: Return of the King: Unrolling the xLSTM Architecture
An unexpected alternative to transformers.
117 words~1 min read