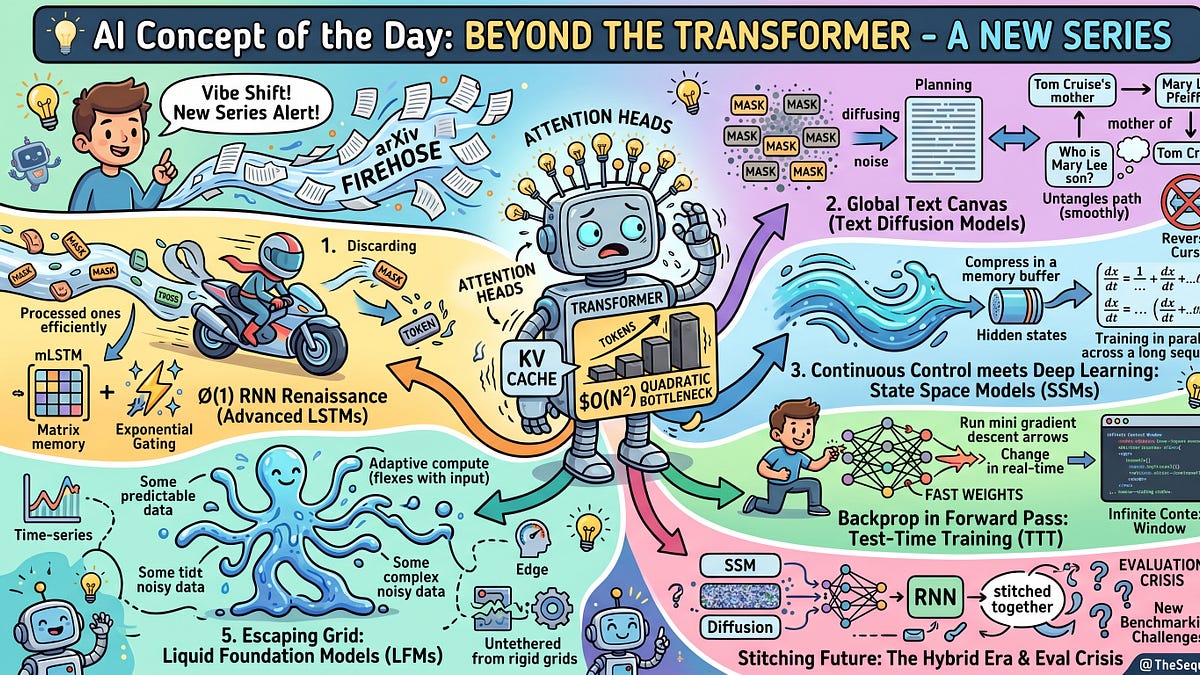
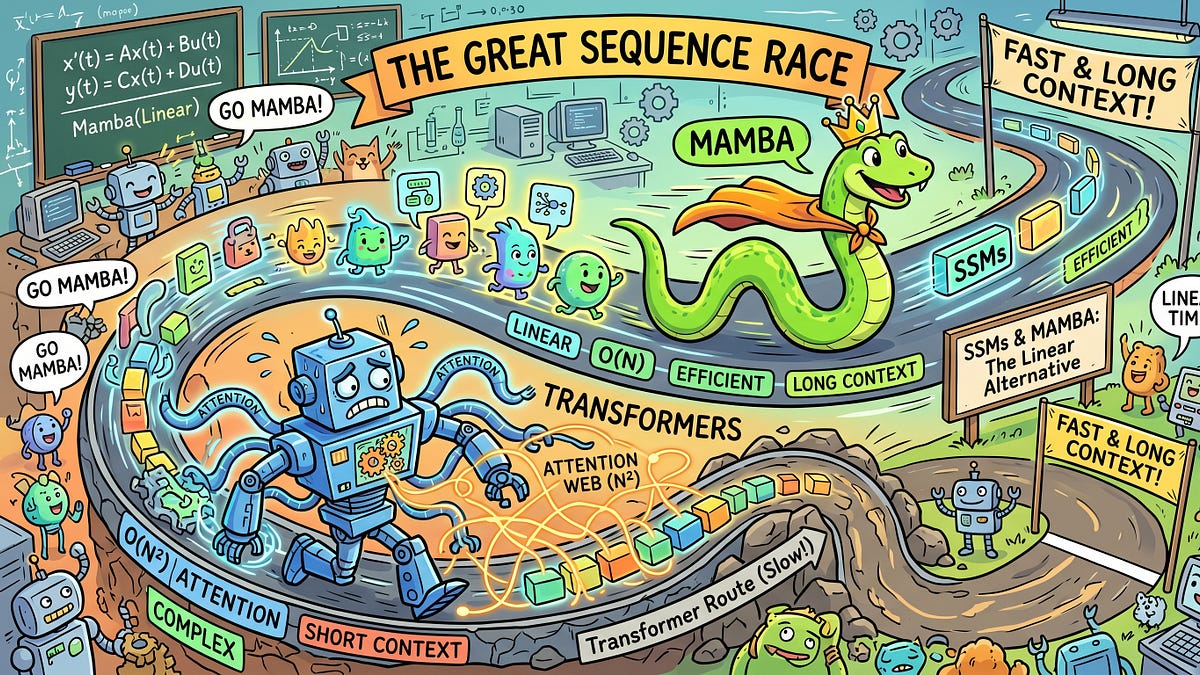
If you were building sequence models circa 2015, your mental model of the world was entirely shaped by Recurrent Neural Networks (RNNs). There was a deep, architectural elegance to them. You feed the network a token, it updates a fixed-size hidden state, and it throws the token away. During inference, the memory footprint was beautifully constant—an $O(1)$ operation that could run efficiently on almost any hardware.Then came 2017. “Attention Is All You Need” dropped, and the entire AI ecosystem pivoted. We traded the elegance of the RNN for the brute-force parallelizability of the Transformer. The Transformer won the hardware lottery because it allowed us to map the entire sequence onto a GPU grid and train it all at once. But we made a devil’s bargain: the Key-Value (KV) cache.In a Transformer, the model must explicitly hold the high-dimensional representations of every previous token in memory to generate the next one. This is an O(N^2) operation. As we push models to 100K, 1M, and now multi-million token context windows, the compute graph becomes mathematically offensive. We are burning vast amounts of high-bandwidth memory simply doing memory reads.This is why, if you watch the arXiv firehose closely right now, you will notice a massive vibe shift. We are witnessing the comeback of the RNN. But this is not a nostalgic return to the classic Long Short-Term Memory (LSTM) networks of the 2010s. The new generation of RNNs features larger states, data-dependent gating, and LLM-era training recipes. They are matching Transformer perplexity at scale, but keeping that sweet $O(1)$ inference cost.Here is a look at the architectures driving the recurrent renaissance.
The Sequence Knowledge #850: The Unexpected Comeback of RNNs
The alternative to transformers you were not thinking about.
268 words~1 min read