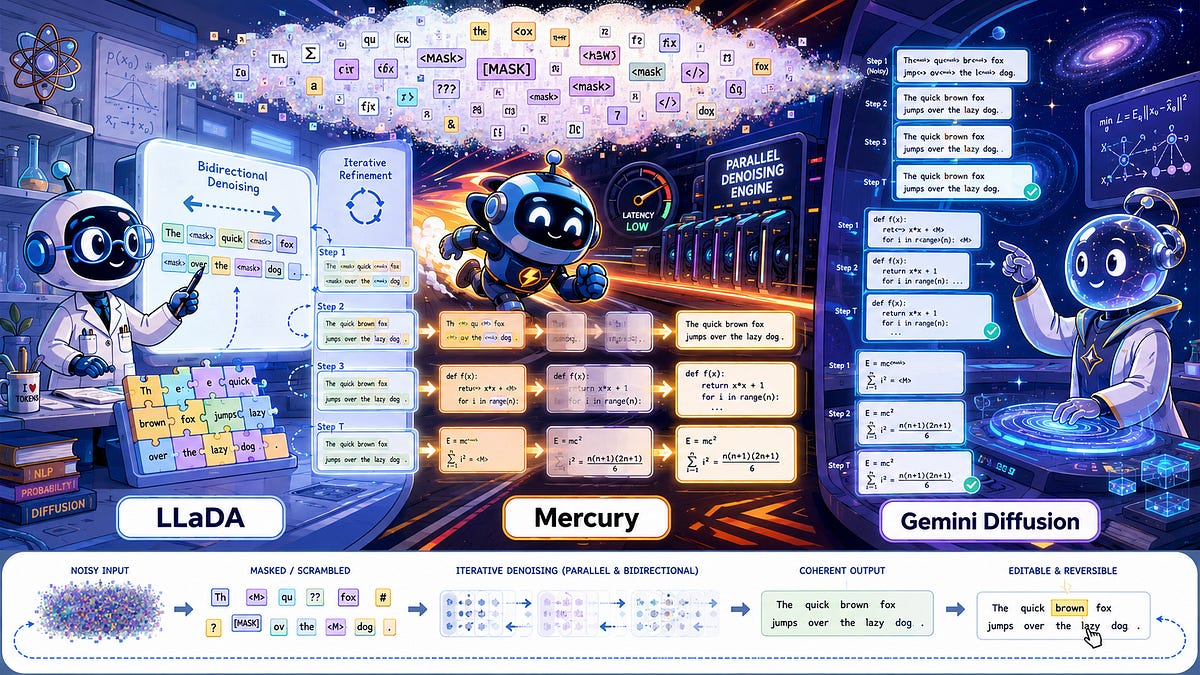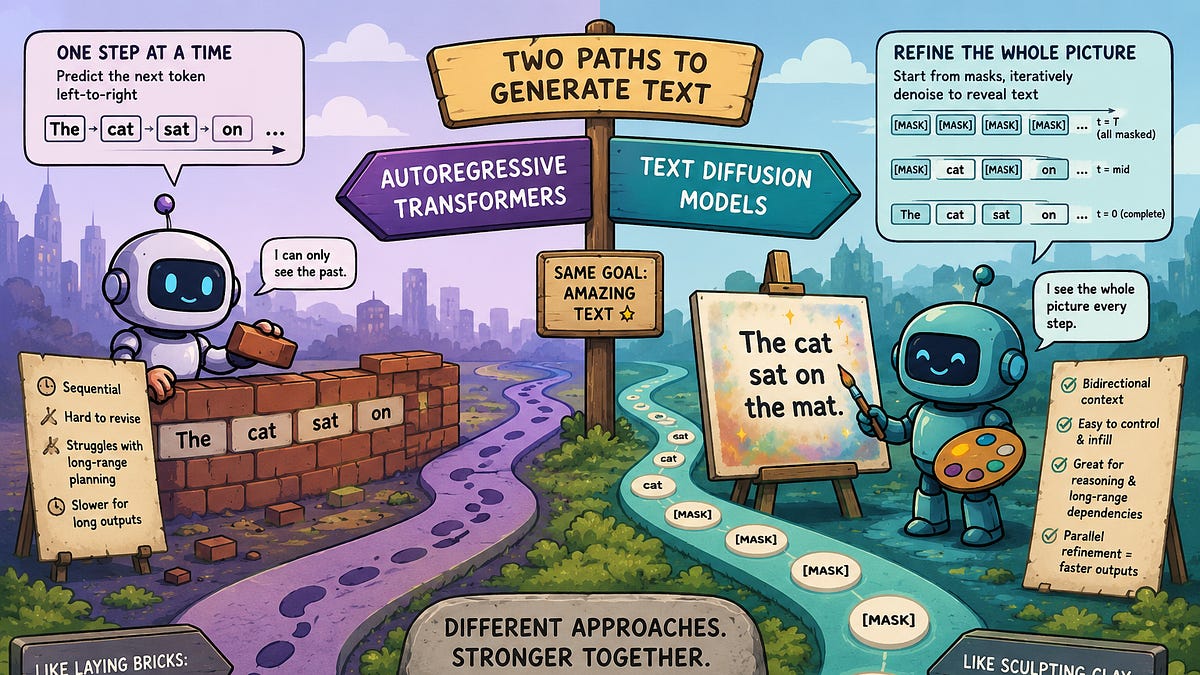
If you look at the architecture of the modern AI boom, it is heavily bifurcated by modality. In the visual domain, we are entirely ruled by diffusion models. From Midjourney to Stable Diffusion to OpenAI’s Sora, the paradigm of starting with pure noise and iteratively denoising it into a high-fidelity image or video has proven to be unreasonably effective.But in the realm of text, diffusion has historically been an afterthought. Large Language Models (LLMs) like GPT-4, Claude, and LLaMA are staunchly autoregressive (AR). They are sequence predictors. They look at the context, predict the next token, append it to the context, and repeat. It is a strictly left-to-right, causal process.For years, the consensus was simple: autoregression is just the native physics of language. But this sequential paradigm has glaring pathologies. Because AR models generate blindly from left to right, they cannot easily engage in global planning. If they make a slight logical error early in a sequence, that error is committed to the context window permanently, leading to cascading failures—a phenomenon often critiqued as “generation drift.” Furthermore, AR models suffer from the “reversal curse”; they can easily recite a poem forward, but if you ask them to recite it backward, their causal attention mechanisms break down entirely.
The Sequence Knowledge #862: Learning About Text Diffusion Models
One of the most credible alternatives to transformers.
207 words~1 min read