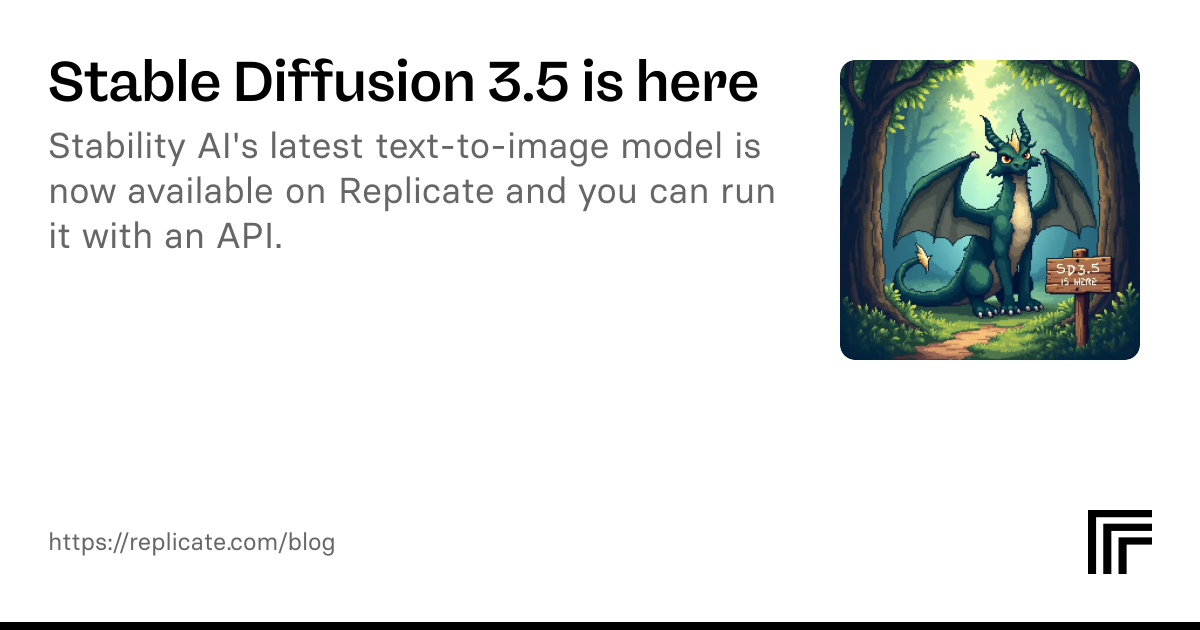
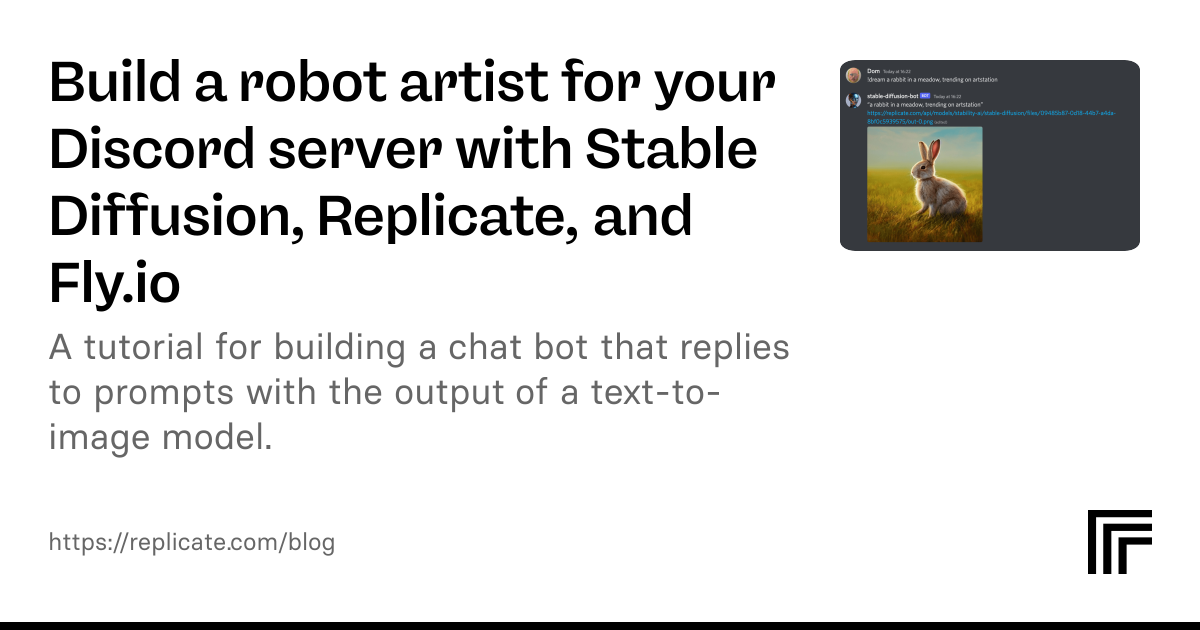
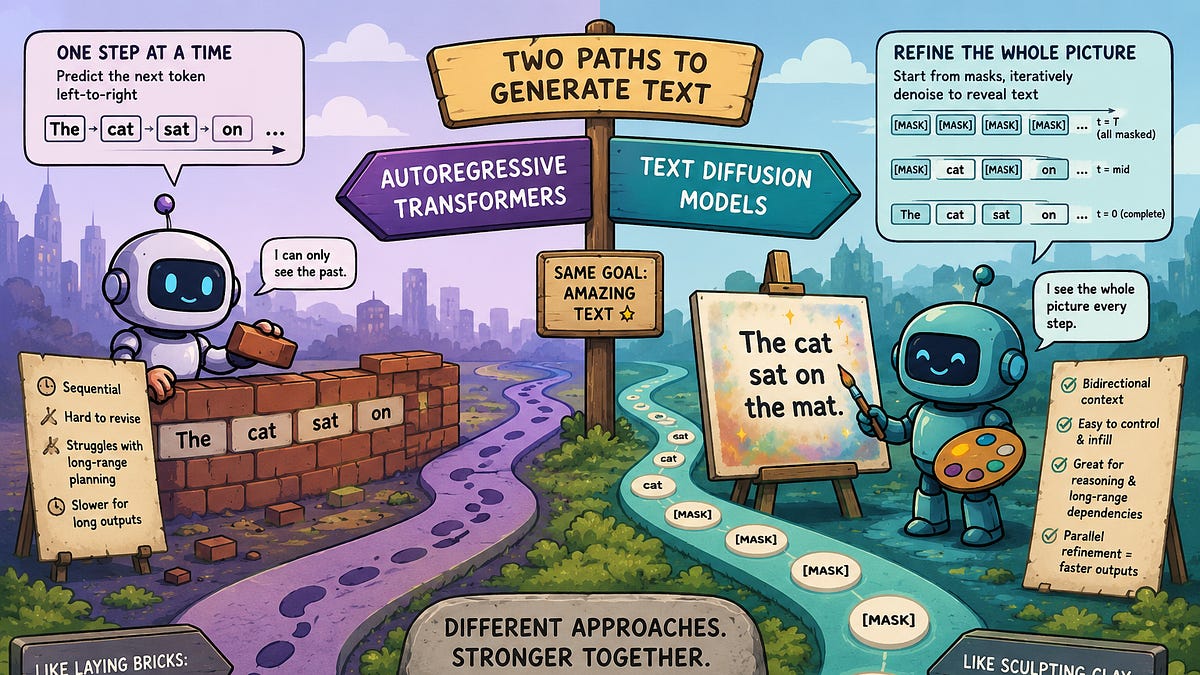
sketch of internet is a series of tubes by Leonardo Da Vinci, VQGAN+CLIP, SD1.5, SD2.1, SDXL.
With the recent release of Stable Diffusion XL fine-tuning on Replicate, and today being the 1-year anniversary of Stable Diffusion, now feels like the perfect opportunity to take a step back and reflect on how text-to-image AI has improved over the last few years.
We’ve seen AI generated images ascend from incomprehensible piles of eyeballs and noise, to high quality artistic images that are sometimes indistinguishable from the brush strokes of a painter, or the detail-oriented rendering of an illustrator.
In this post, we’ll take a whirlwind tour of the evolution of text-to-image AI, to get a sense of how far we’ve come over the last few years, from early GAN experiments to the latest diffusion models.
Before Diving In