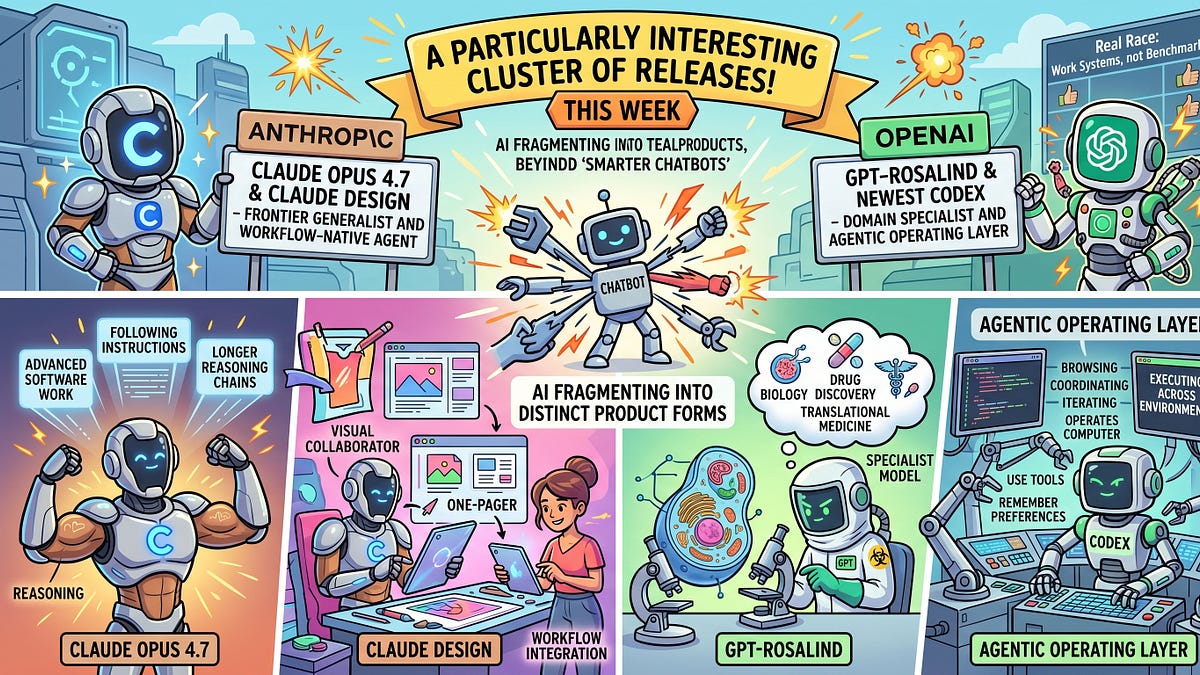
We start a new series about alternatives to transformers including text diffusion models, SSMs and many more. The opinion installment will discuss a hot topic: MCP or CLIs?The AI of the week section dives into Claude Opus 4.7.This week brought a particularly interesting cluster of releases from Anthropic and OpenAI. Anthropic pushed on both the model and product fronts with Claude Opus 4.7 and the new Claude Design, while OpenAI expanded in two different directions with GPT-Rosalind and the latest Codex. Put together, these launches say something important about where the frontier is heading. The story is no longer just about smarter chatbots. It is about AI splitting into distinct product forms: the general-purpose reasoning model, the domain specialist, and the workflow-native agent.Anthropic’s side of the week was especially revealing because it showed both ends of that transition. Claude Opus 4.7 looks like a refinement of the frontier generalist: stronger for advanced software work, better at following instructions, and more reliable in longer chains of reasoning. But Claude Design is the more interesting signal. It packages Claude not just as a model that can describe visual work, but as a collaborator for actually producing it—designs, prototypes, slides, and one-pagers. That matters because it turns design from a prompting exercise into a workflow. Anthropic is not just improving a model; it is carving out a new interface category where reasoning and visual production start to merge.OpenAI’s releases tell a parallel story, but from a different angle. GPT-Rosalind represents the rise of the specialist model: a system built specifically for biology, drug discovery, and translational medicine rather than a general model stretched into a scientific costume. That is a meaningful shift. The next wave of AI advantage will not come only from one model doing everything reasonably well. It will come from systems that are deeply adapted to the language, tools, and constraints of high-value domains. Rosalind suggests that science is becoming one of the first places where that specialization is explicit, productized, and strategically central.Then there is Codex, which may be the clearest signal of all. The newest version is not just about code generation. It can operate a computer, use tools and apps, remember preferences, connect to remote environments, and handle ongoing work over time. That changes the meaning of “coding assistant.” Codex is inching toward something broader: an agentic operating layer for software and knowledge work. The important shift is not that it writes better code. It is that it increasingly participates in the surrounding workflow—browsing, coordinating, iterating, and executing across environments rather than waiting passively for the next prompt.The deeper pattern across Anthropic and OpenAI is that frontier AI is fragmenting into real products. Anthropic is pushing the frontier generalist into adjacent creative workflows. OpenAI is pushing both specialization and agentic execution. And together they are making the competitive landscape much more interesting. The real race is no longer just who has the smartest model on a benchmark. It is who can turn intelligence into the most compelling system for actual work. That is what made this week’s releases worth watching. AI Lab: Together AI, University of Illinois Urbana-Champaign, The University of Texas at Austin, Princeton University, and Stanford University Summary: Diffusion language models traditionally lag behind autoregressive models because they lack introspective consistency, meaning they do not reliably agree with their own generated tokens. To address this, the authors introduce the Introspective Diffusion Language Model (I-DLM), which utilizes a novel strided decoding algorithm to simultaneously verify and generate tokens, matching autoregressive model quality while significantly improving serving efficiency.AI Lab: FAIR at Meta and NYU Courant Institute and CDS Summary: This paper challenges the prevailing assumption that large language model reinforcement learning requires strictly fresh, on-policy data by demonstrating the effectiveness of experience replay. Through a systematic study, the authors show that a well-designed replay buffer can drastically reduce expensive inference compute costs during training while maintaining or even improving the model’s final performance and output diversity.AI Lab: NVIDIA Summary: Generating large-scale 3D scenes using video diffusion models often suffers from spatial forgetting and temporal drifting over long camera trajectories. Lyra 2.0 mitigates these degradations by utilizing per-frame 3D geometry for history retrieval and self-augmented training to correct drift, enabling the creation of persistent, explorable 3D worlds from a single input image.AI Lab: University of California, San Diego and Together AI,Summary: Looped architectures offer a way to increase a model’s compute without increasing its parameter footprint by repeatedly passing activations through a block of layers, but existing training methods for these models are often unstable. To resolve this, the authors propose Parcae, a novel, stable looped architecture that constrains the spectral norm of its injection parameters, enabling the discovery of predictable scaling laws for both training and test-time compute that improve model quality while keeping parameter counts fixed.AI Lab: Google DeepMind Summary: Conventional visual generative models rely on deep stacks of unique transformer layers, whereas this paper proposes Elastic Looped Transformers (ELT) that use iterative, weight-shared blocks to drastically reduce parameter counts. By utilizing an Intra-Loop Self Distillation (ILSD) training method, ELT achieves high-fidelity image and video generation while enabling Any-Time inference, allowing users to dynamically trade off computational cost and generation quality at test-time.AI Lab: Johns Hopkins University Summary: Current instruction hierarchy paradigms use a small, fixed set of privilege levels, which is inadequate for real-world agents receiving conflicting instructions from numerous heterogeneous sources. To address this limitation, the authors introduce the Many-Tier Instruction Hierarchy (ManyIH) and an accompanying benchmark, MANYIH-BENCH, revealing that current frontier models perform poorly when resolving conflicts across arbitrarily many privilege levels.OpenAI released GPT-Rosalind, a new frontier reasoning model for life science research. Google announced a release of the Gemini app for macOS. OpenAI unveiled Codex for (almost) everything, a new agents that extends Google released Chrome Skills to integrate AI workflows. Anthropic Labs unveiled Claude Design, a collaborative experience to create visual artifacts. Alibaba Qwen open sourced Qwen3.6-35B-A3B, a more efficient version of its marquee agentic coding model.Cursor in talks at $50B valuation — Four-year-old Cursor is nearing a $2B+ round led by returning backers Thrive and a16z at a $50B pre-money valuation (with Battery and Nvidia also expected to participate), as it projects ending 2026 at a $6B+ ARR run rate. OpenAI’s former product chief and Sora head leave — Kevin Weil (ex-CPO, most recently running the OpenAI for Science team, which is being decentralized into other research groups) and Bill Peebles (the researcher behind Sora) both announced their departures on Friday as OpenAI sheds “side quests” to focus on enterprise AI and its forthcoming superapp — with enterprise CTO Srinivas Narayanan reportedly leaving as well. Cerebras files publicly for US IPO (second attempt) — AI chipmaker Cerebras Systems publicly filed its S-1 with the SEC on Friday, disclosing $510M in 2025 revenue and $87.9M of net income (vs. a $484.8M loss on $290M of revenue in 2024), and plans to list on Nasdaq as “CBRS” with Morgan Stanley, Citi, Barclays, and UBS leading the offering. Factory hits $1.5B valuation — Enterprise AI coding startup Factory raised a $150M Series C led by Khosla Ventures at a $1.5B valuation, adding Keith Rabois to its board and bringing customers like Morgan Stanley, EY, and Palo Alto Networks onto its “Droids” agent platform. Upscale AI at $2B valuation — Seven-month-old AI infrastructure startup Upscale AI is reportedly in talks to raise $180M–$200M at a ~$2B valuation, its third round since launching, with Tiger Global, Xora, and Premji Invest as existing backers despite no shipped product yet. Hightouch hits $100M ARR — Hightouch told TechCrunch it has reached $100M ARR — $70M of which came in the 20 months since launching its brand-aware AI marketing product used by Domino’s, Chime, PetSmart, and Spotify. → TechCrunch exclusive; no earlier original source found.Gitar exits stealth with $9M — Gitar, founded by ex-Uber/Google/Intel engineers Ali-Reza Adl-Tabatabai and Gautam Korlam, emerged from stealth with a $9M seed led by Venrock (with Sierra Ventures) to build AI “agentic quality gates” for code review and CI validation. TSMC Q1 profit beats estimates — TSMC reported Q1 2026 net income of NT$572.5B (up 58% YoY) on revenue of US$35.9B (up 40.6% YoY in USD terms), guided full-year revenue growth above 30%, and said Middle East conflict has not dented AI chip demand. Accel raises $5B for late-stage AI bets — Accel announced $5B in fresh capital — $4B for its fifth Leaders Fund (targeting 20–25 ~$200M late-stage checks in AI, robotics, defense, and data center infrastructure) plus a $650M LP sidecar — after Anthropic and Cursor marks soared. Jane Street invests $1B in CoreWeave, commits $6B in cloud spend — Jane Street committed ~$6B to use CoreWeave’s AI cloud (including NVIDIA Vera Rubin capacity) and separately bought $1B of Class A stock at $109/share, bringing total commitments to $7B. No posts
The Sequence Radar #845: Last Week in AI: Anthropic and OpenAI Enter a New Phase
Major releases by the two fierce competitors
1,470 words~7 min read