KV cache and PagedAttention: what they do and why they matter
Your production LLM server is running behind schedule. You deployed a 70B model on four A100s with 80 GB each -- within spec, within budget -- but the time-to-first-token is creeping up as concurrent users increase. By lunch, latency is double what it was at 8 AM. You check GPU memory and find that 70% of HBM is consumed by what nvidia-smi reports as "tensor buffers," but which are actually the cached transformer states of a dozen long-running conversations that nobody cleaned up. You restart the server. It works again. By 4 PM, the same slowdown is back.
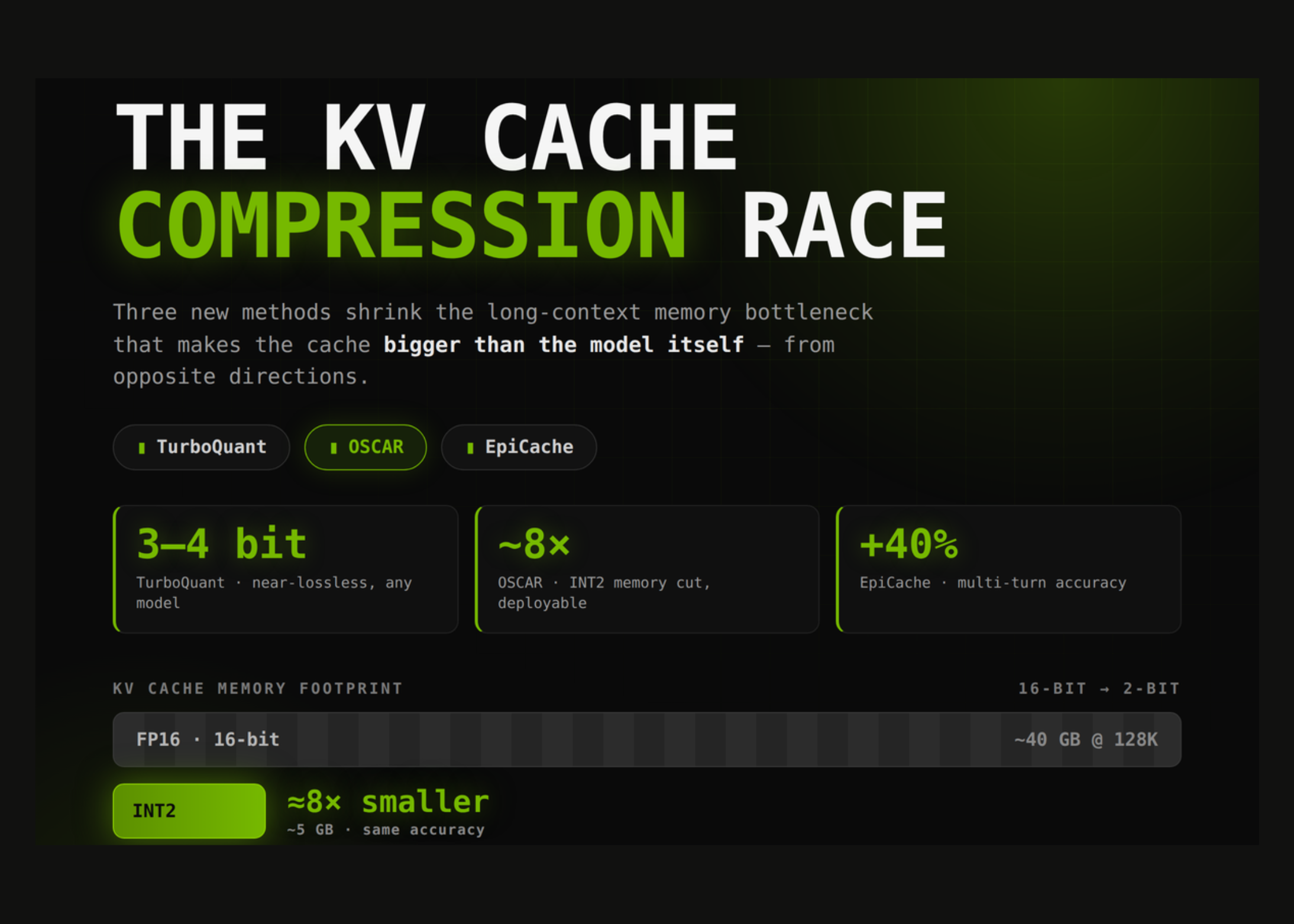
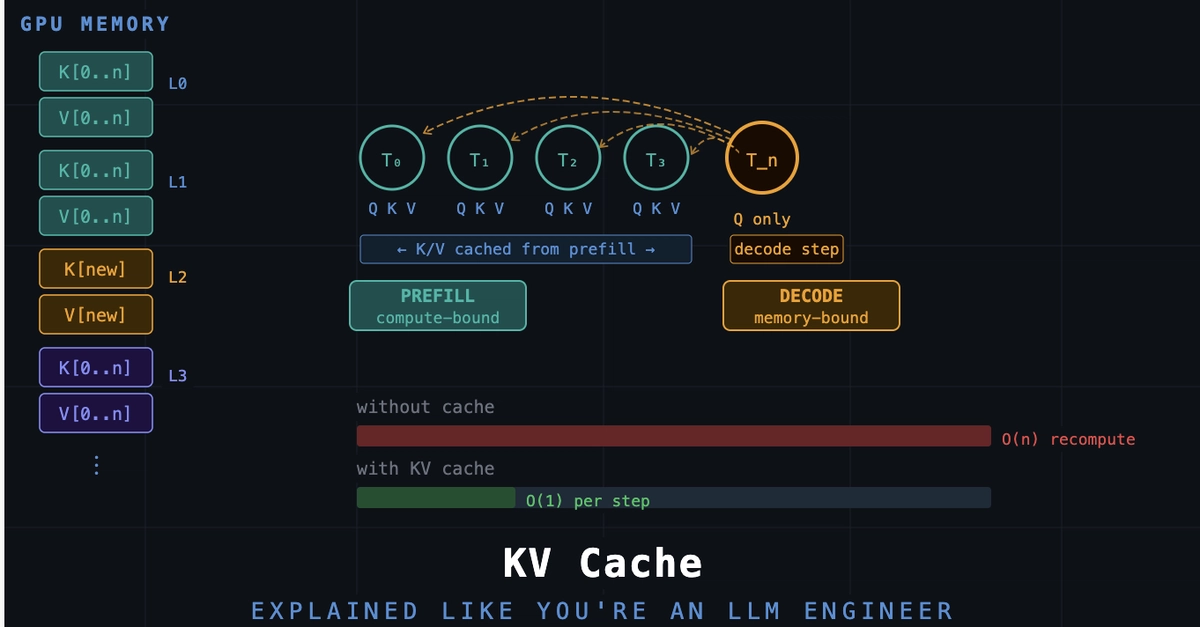
This is the KV cache memory problem, and it is the single biggest operational bottleneck in production LLM serving on GPUs. This post explains what the KV cache actually stores, why it grows without bound during a conversation, and how PagedAttention -- the technique that powers vLLM -- solves it with OS-inspired memory management.
Why the KV cache matters
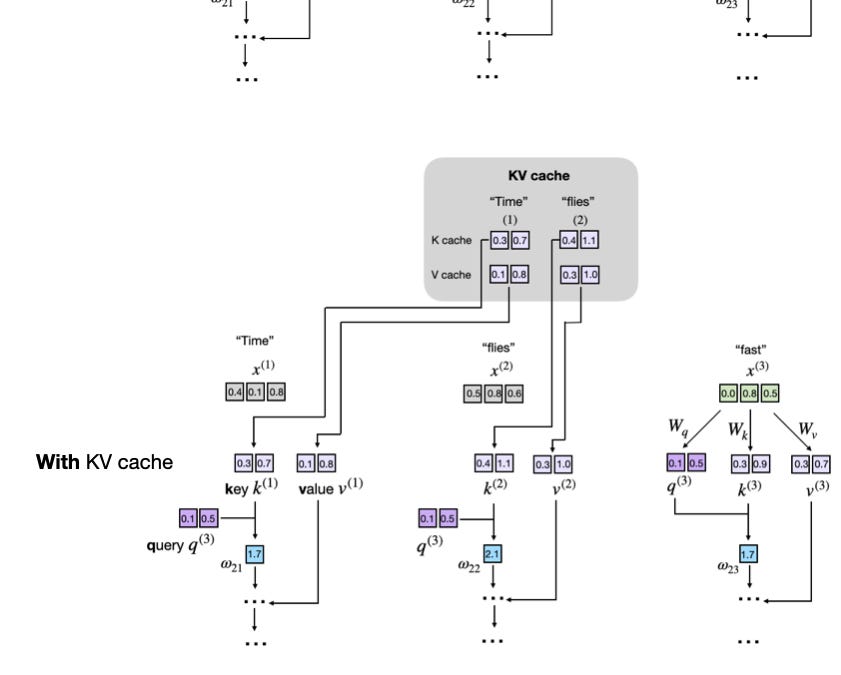
The KV cache is not optional. Every autoregressive transformer generates tokens one at a time. For token N, the attention mechanism needs the Key and Value tensors from tokens 0 through N-1. Recomputing those from scratch for every new token would be O(N^2) per step -- catastrophic for any conversation longer than a few hundred tokens. Instead, the inference engine caches the K and V tensors from prior tokens and appends to them on each step. That structure is the KV cache.