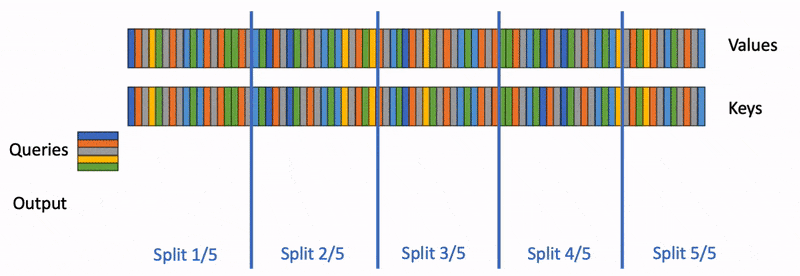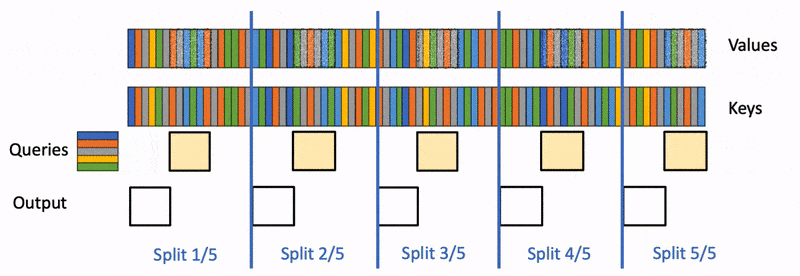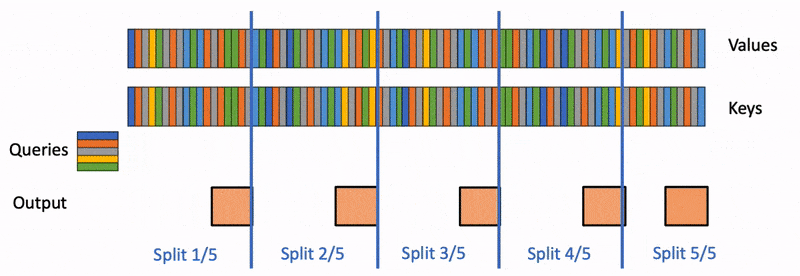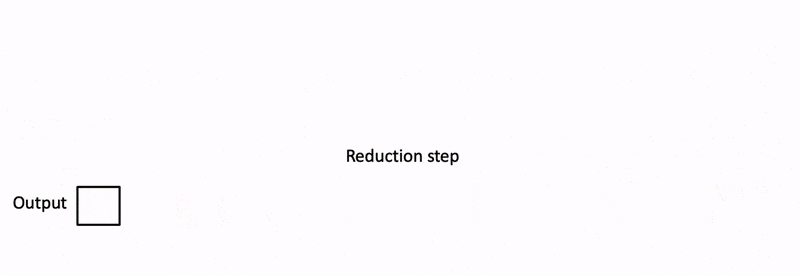
In the previous article, we saw how a language model processes a prompt during prefill, then generates tokens one at a time during decode, and uses KV cache to avoid repeated computation. In the real world, inference servers handle hundreds or thousands of requests at the same time. How a server schedules those requests determines whether the GPU is doing useful work or sitting idle waiting.
In this tutorial, we take a hands-on approach to understand:
Why does static batching create a bottleneck and waste tokens on padding
How dynamic scheduling admits new requests the moment a slot opens
How ragged batching allows multiple prompts to be processed together