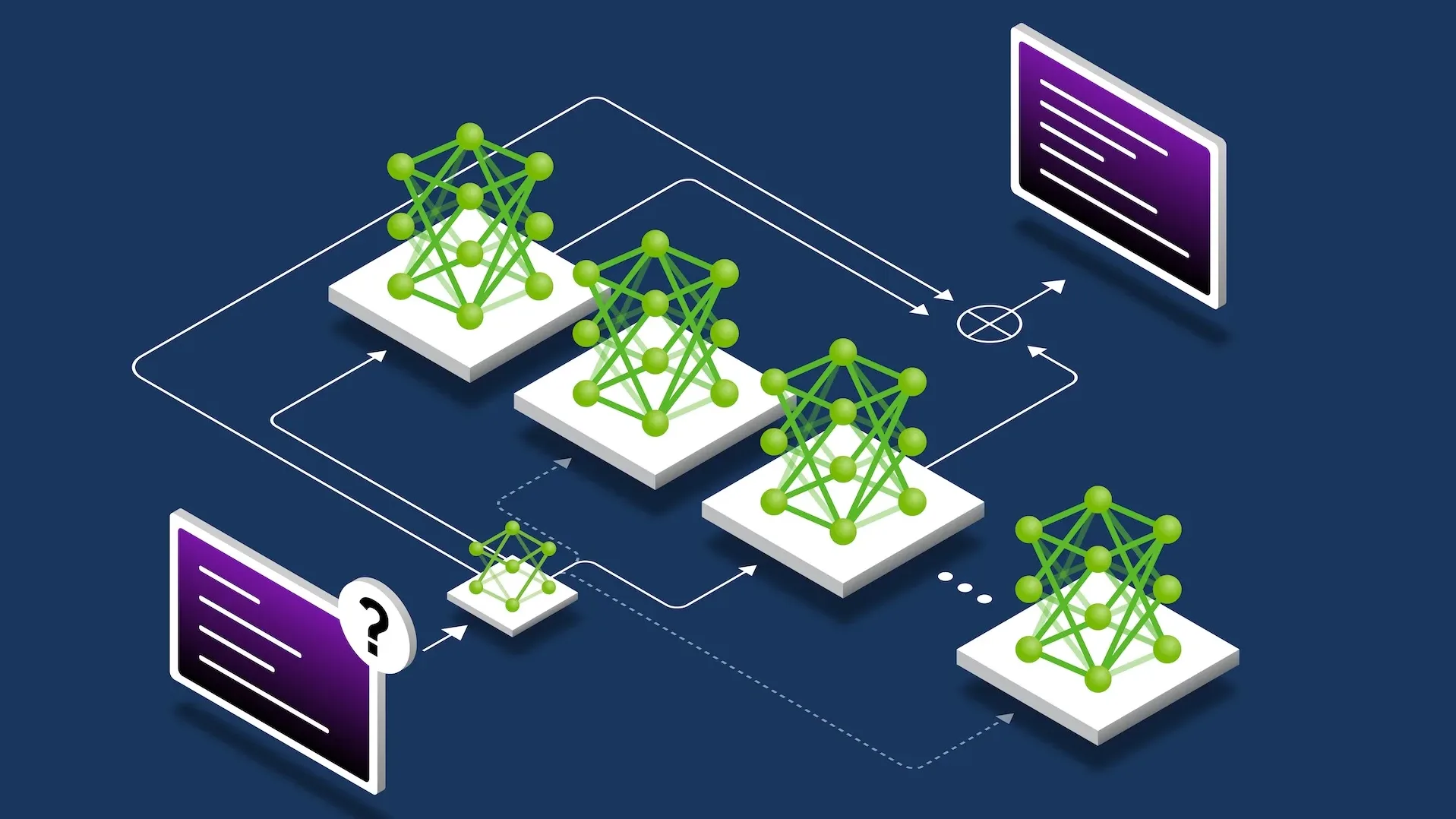
TL;DR: The same 16 GPUs, twice the users. Your GPU bill remains flat while capacity doubles. A cluster that handled 20 concurrent users now handles 200. These numbers are made possible by llm-d’s inference scheduler, built to route every request across a distributed cluster with visibility into every node, every queue, and every cache. Large language model (LLM) requests are slow, non-uniform, and expensive—the inference scheduler is built for exactly that.The pattern that works everywhere elseEvery GPU-hour has a price, the question is how much work you are getting out of it.Kubernetes is how distributed services get built, deployed, and operated at scale. In a standard Kubernetes configuration, you define a deployment, set a replica count, and a Kubernetes service gives you a front door with round-robin load balancing across all your pods. For REST APIs, web services, and microservices, this pattern is essentially perfect. Requests are fast, uniform, and each one takes roughly the same sub-second time to complete.But the moment you start serving large generative models at scale, such as Llama, Mistral, or GPT-class open source models, that assumption no longer holds.Where round robin reaches its limitsLLM inference requests are not like normal HTTP requests, and the differences are what break standard load balancing:Time variability: A request can take less than a second or over a minute, depending on what the model is asked to do. Round robin distributes requests, not work. If one replica gets a sequence of long, expensive requests, it becomes a bottleneck while another sits largely idle.Shape variability: Short prompts with long generated responses behave differently from long prompts with short responses. The compute profile, the memory pressure, and the time to completion are all different.Phase variability: Every inference request has 2 internal phases: prefill, which processes the entire input prompt in one parallel sweep, and decode, which generates the response 1 token at a time. These 2 phases have different resource profiles, different durations, and different sensitivity to load. A system that can't tell them apart can't optimize for either.Round robin was built for workloads where requests are short-lived, uniform, and cheap. A scheduler that can't see inside the request treats them as the same thing.
The same 16 GPUs, twice the users: Inference-aware routing for LLM clusters
Learn how inference-aware routing can double your large language model (LLM) cluster's capacity while keeping your GPU bill flat. Discover the benefits of llm-d's inference scheduler and how it optimizes cluster-level coordination for LLM inference.
1,268 words~6 min read