Why Agent Workloads Are Expensive
LLM inference costs always scale with context length. In agent workloads, this becomes especially expensive. Consider a coding agent helping a developer refactor a module. The agent reads the file, proposes an edit, applies it, runs tests, sees a failure, reads the error log, and tries again.
Each of these steps is a separate LLM call, and each call carries the entire conversation history. By the final step, the context has grown to 30K+ tokens, but the new information is just a few lines of test output. The model re-computes everything from scratch every time.
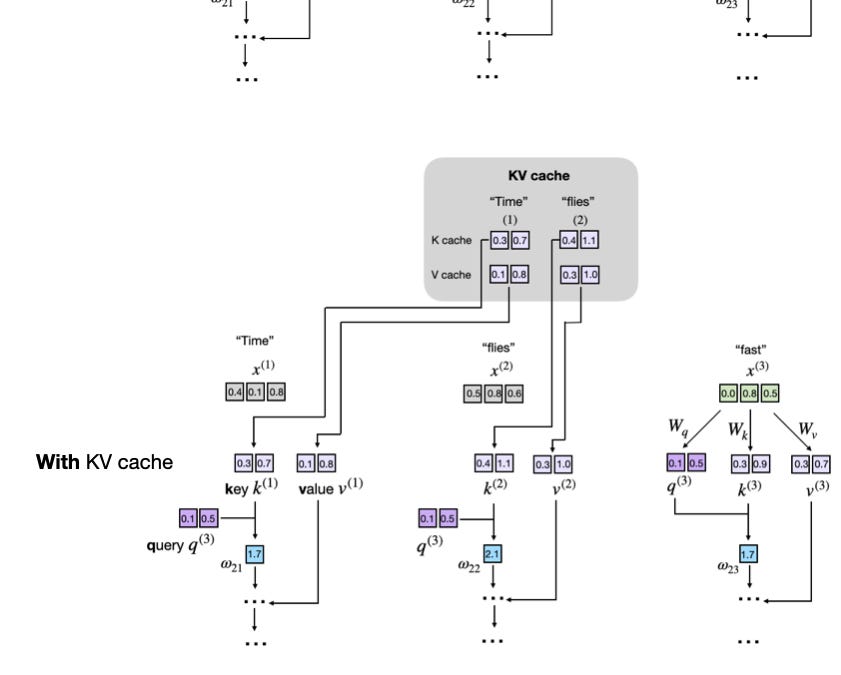
KV-Pool: Reuse What You Already Computed
To maximize GPU utilization, improve throughput, and reduce inference latency, we introduced an optimized KV-Pool service.