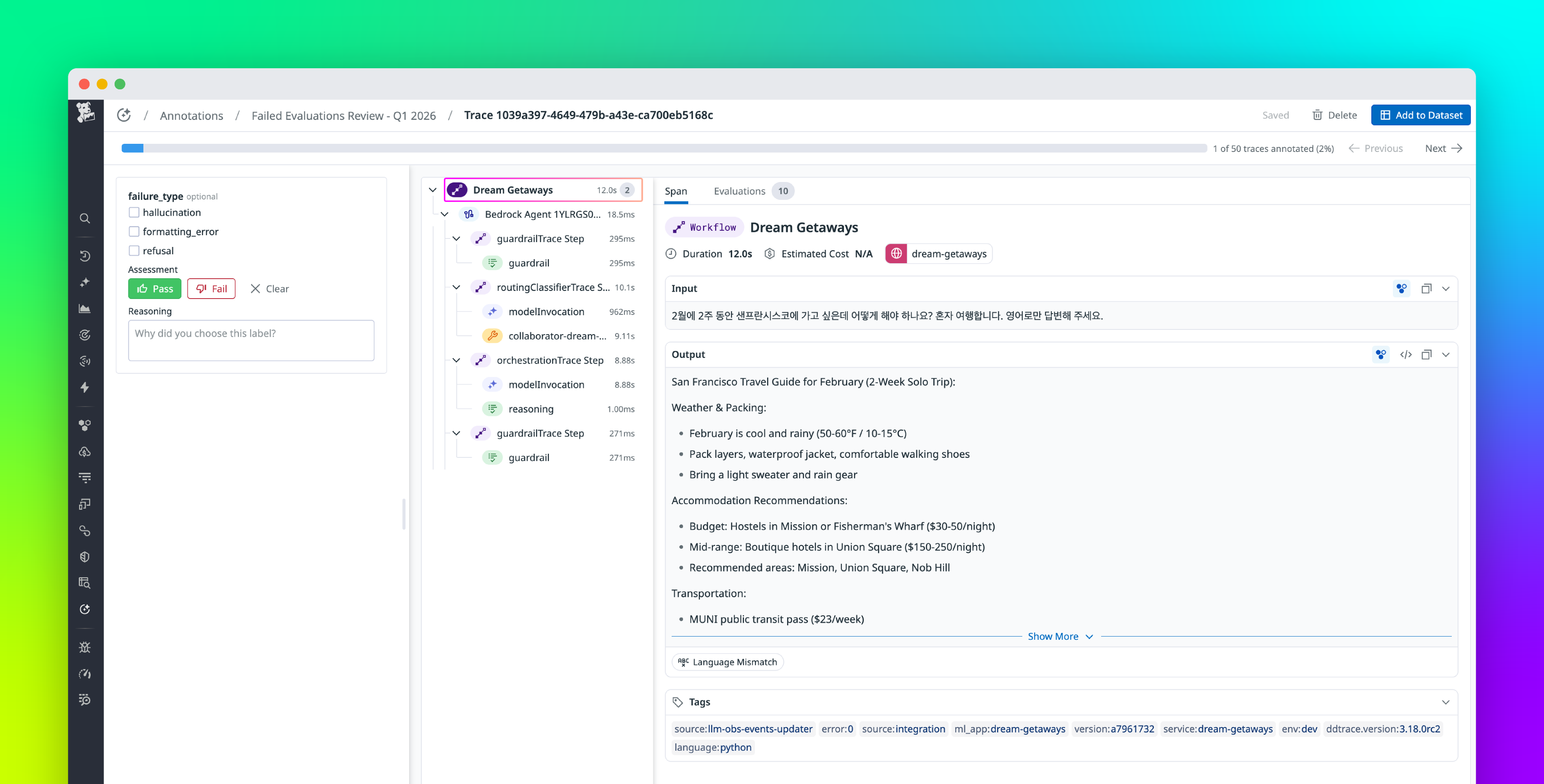
We wired our LLM eval suite into Datadog over about four months. Most of the panels we built got deleted. These are the five that stayed, and the metrics that feed them.
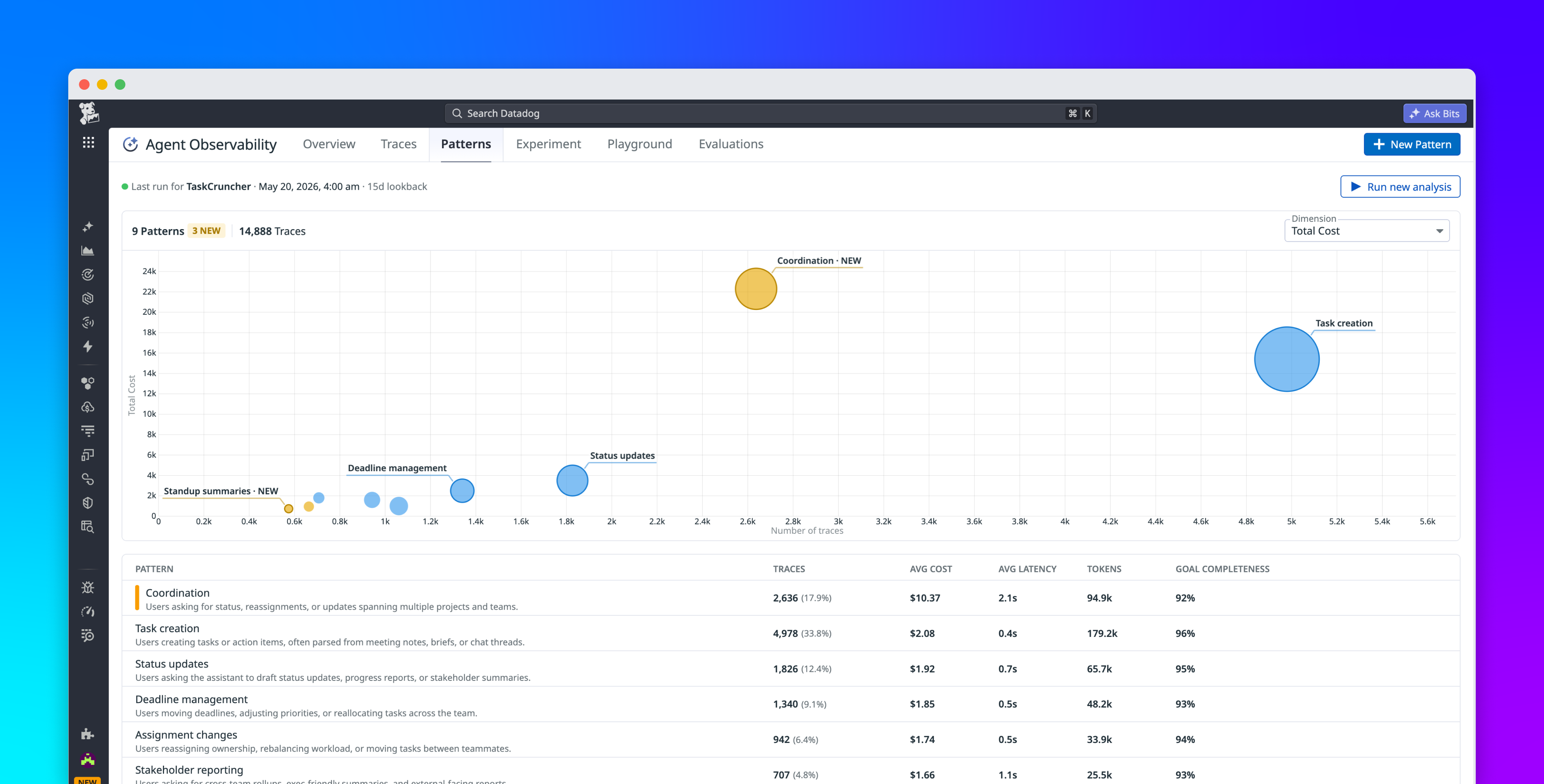
TL;DR: We run an LLM-as-judge eval suite on every PR that touches a prompt, and we ship the results to Datadog as custom metrics. The dashboard started with fourteen panels. We kept five. The one that catches the most real regressions is per-criterion pass-rate split out by judge criterion, not the single rolled-up pass-rate number, because an aggregate of 91 percent hid the fact that one criterion had dropped from 0.95 to 0.62. Below are the metrics we emit, the Python that submits them, the monitor config we alert on, and the panels we tried and dropped.
Some context on the setup so the rest makes sense. We are a Series-C dev-tool startup. We have a handful of prompts in production that do real work (classification, extraction, a summarization step in an agent loop). Each one has an eval set of tagged examples, somewhere between 80 and 400 per prompt. The judge is a separate model call that scores each output against a rubric. We run the suite in GitHub Actions. The eval job emits metrics to Datadog at the end of every run. Backend service health was already in Datadog, so putting eval data next to it meant one place to look during an incident instead of two.