Without experiment infrastructure to help you test your LLM applications, every research session starts with the same questions: What have we tried previously? What were the numbers? Which prompt version produced that result? Why did we discard that approach? The answers live in scattered notes, terminal history, and half-remembered conversations. Each handoff between sessions loses context. In practice, iteration can slow down as teams get bogged down in testing and analysis.
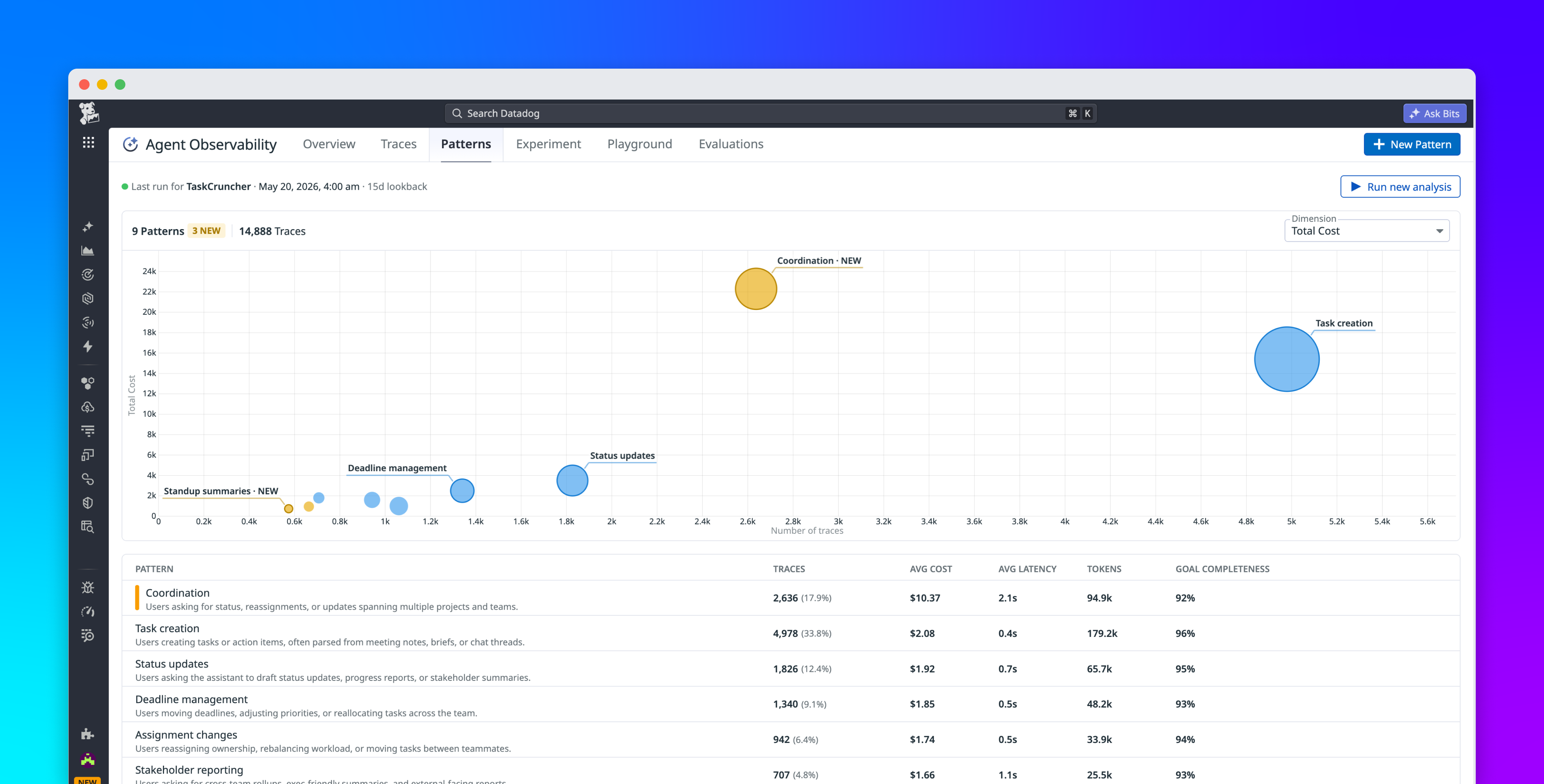
The Datadog team responsible for building and maintaining Database Monitoring (DBM) needed to tackle these challenges in order to explore whether an AI agent could augment DBM’s automated query optimization recommendations. The DBM team used Karpathy’s autoresearch tool to trigger 23 autonomous experiments that brought the query optimization recommendation agent from precision scores of P=0.54 to P=0.86 overnight. Through this iterative process, the team proceeded through three phases:
Optimizing the prompt and tool chainRightsizing the model for an appropriate cost-performance tradeoffBreaking the LLM call into two separate passes to break through a final performance barrier
In this post, we’ll discuss the autoresearch-powered experimentation process in depth, exploring how the team planned and executed rapid iteration of the agent by using LLM Observability Experiments to track, analyze, and act on the experiment results.