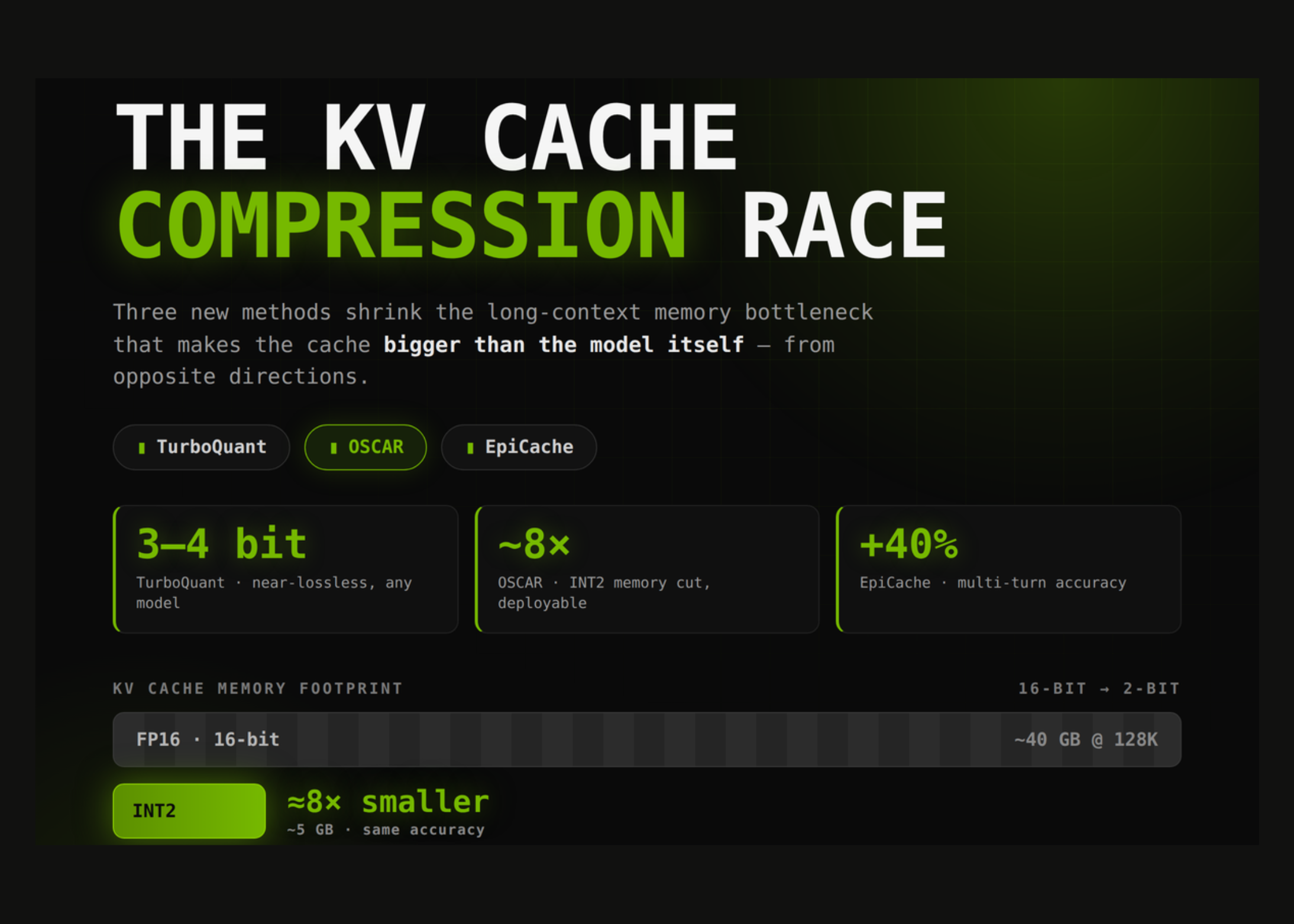
AuthorsMinsoo Kim, Arnav Kundu, Han-Byul Kim, Richa Dixit, Minsik ChoModern large language models (LLMs) extend context lengths to millions of tokens, enabling coherent, personalized responses grounded in long conversational history. However, the Key-Value (KV) cache grows linearly with the extended dialogue history, causing the model’s memory footprint to quickly exceed device limits. While recent KV cache compression methods attempt to reduce memory usage, most apply cache eviction after processing the entire context, incurring unbounded peak memory usage. Additionally, query-dependent eviction narrows the cache semantics to a single query, leading to failure cases in multi-turn conversations. In this paper, we introduce EpiCache, a training-free KV cache management framework for long conversational question answering (LongConvQA) under fixed memory budgets. EpiCache bounds cache growth through block-wise prefill and preserves topic-relevant context via episodic KV compression, which clusters conversation history into coherent episodes and performs episode-specific KV cache eviction. Across three LongConvQA benchmarks (LongMemEval, Realtalk, and LoCoMo), EpiCache improves accuracy by up to 30%, achieves near full-cache accuracy under 4-6x compression, and reduces latency and peak memory by up to 2.4x and 3.7x, respectively.Related readings and updates.Serving transformer language models with high throughput requires caching Key-Values (KVs) to avoid redundant computation during autoregressive generation. The memory footprint of KV caching is significant and heavily impacts serving costs. This work proposes to lessen these memory requirements. While recent work has largely addressed KV cache reduction via compression and eviction along the temporal axis, we argue that the depth dimension offers…Read moreLarge Language Models (LLMs) are increasingly used in applications requiring long context
EpiCache: Episodic KV Cache Management for Long-Term Conversation on Resource-Constrained Environments
Modern large language models (LLMs) extend context lengths to millions of tokens, enabling coherent, personalized responses grounded in long…
311 words~1 min read