Compressing KV cache via low-rank projections — the attention mechanism behind DeepSeek-V2/V3 and Kimi K2.x
Why This Matters
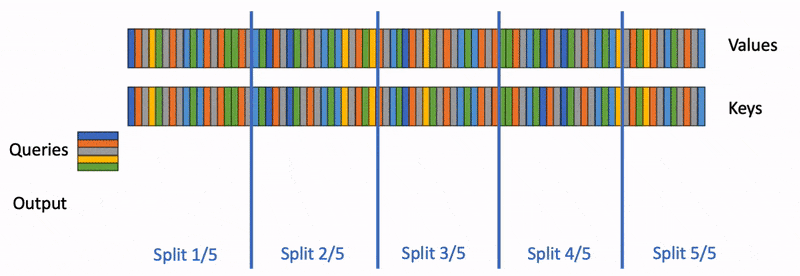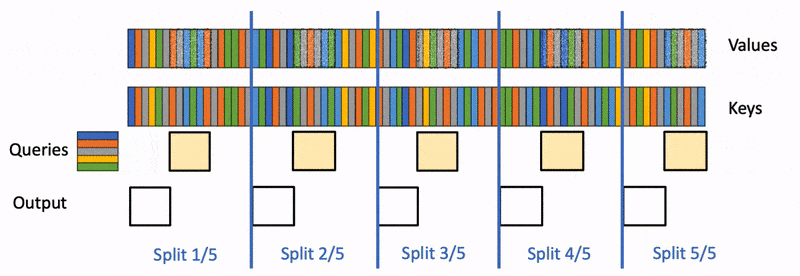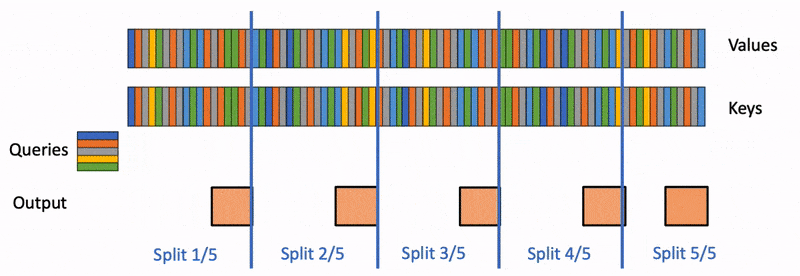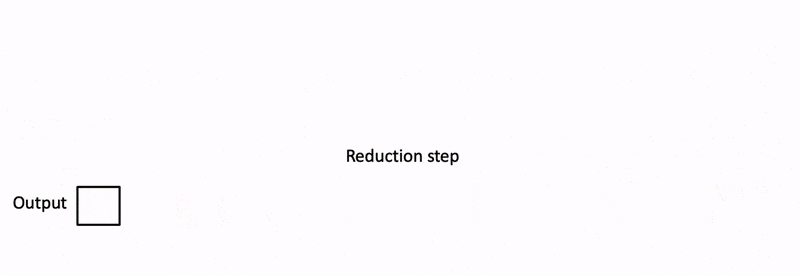
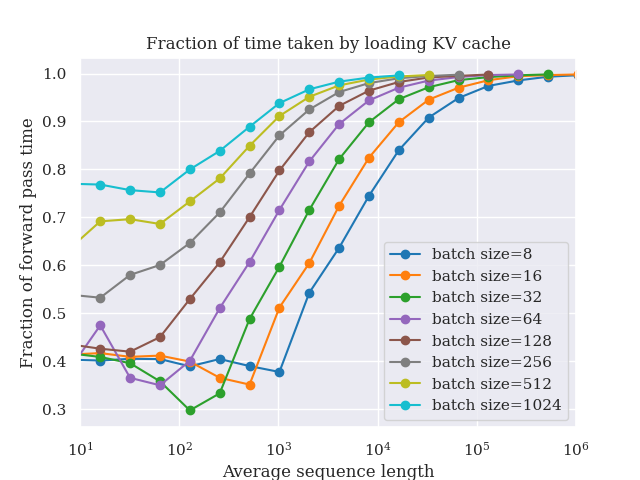
Multi-Head Latent Attention (MLA) is the attention variant that replaces standard Multi-Head Attention (MHA) in DeepSeek-V2, DeepSeek-V3, and Kimi K2.x models. Instead of caching full KV pairs per head, MLA projects them into a low-dimensional latent space, achieving 5-10x KV cache compression with minimal quality loss.
MLA changes how prefix caching, chunked prefill, and paged attention must be implemented
Formal Definition