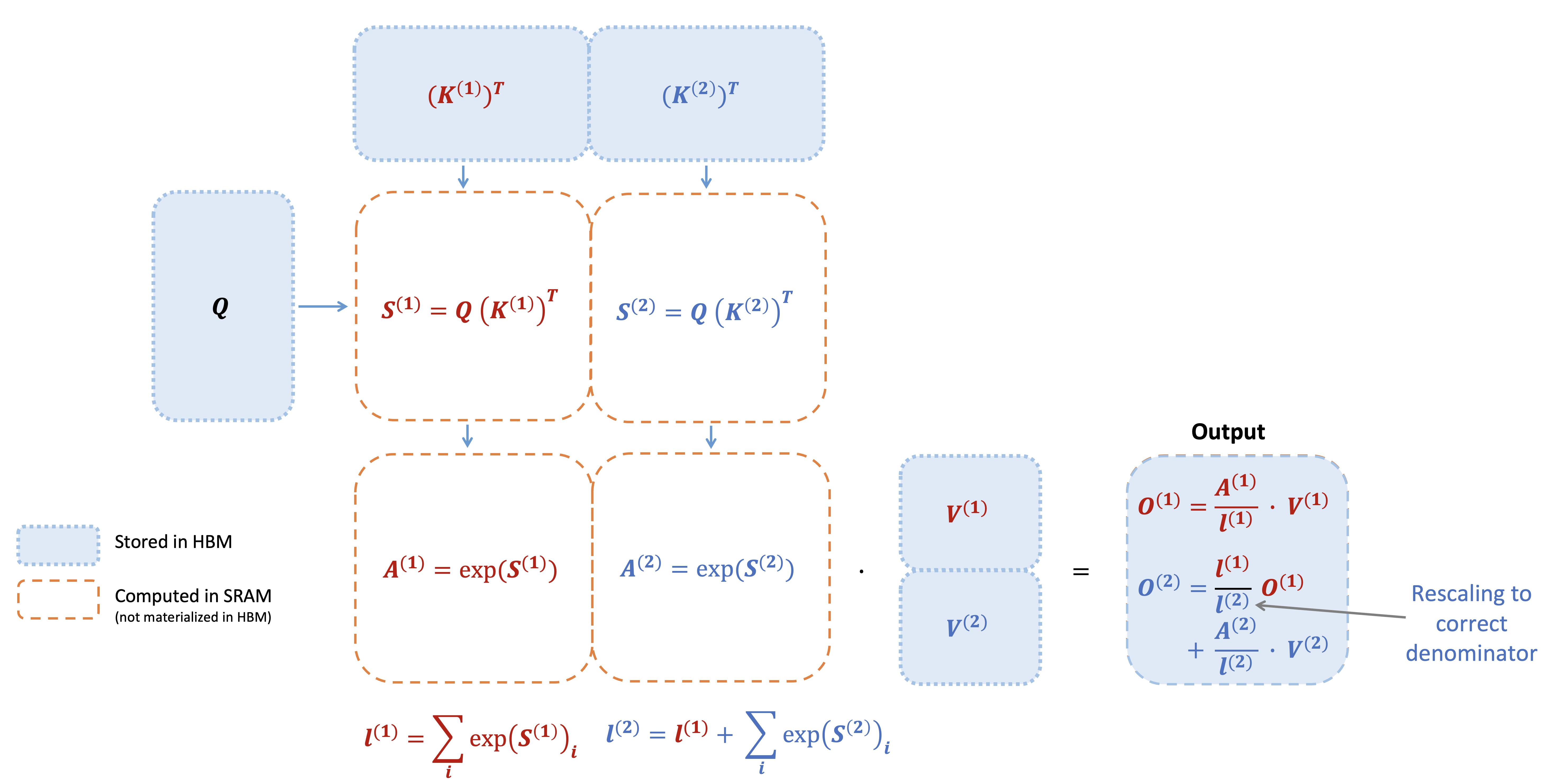
Linear attention replaces the unbounded KV cache of softmax attention with a fixed-size recurrent state. This cuts sequence mixing to linear time and decoding to constant memory. The hard part is not what to forget. It is how to edit a compressed memory without scrambling existing associations.
NVIDIA has released Gated DeltaNet-2, a linear attention layer that targets that bottleneck. The model decouples the active memory edit into two channel-wise gates. It is trained at 1.3B parameters on 100B FineWeb-Edu tokens. It outperforms Mamba-2, Gated DeltaNet, KDA, and Mamba-3 across the researchs benchmark suite.
A recurrent linear attention layer stores a matrix state St and reads it with the query. DeltaNet adds an active edit by subtracting the value currently associated with the current key. It uses a scalar step size βt to control how much to overwrite. Mamba-2 adds a data-dependent scalar decay αt for global forgetting. Gated DeltaNet combined both operations, but both gates remained scalar per head.
Kimi Delta Attention (KDA) refines the decay side. It replaces the scalar αt with a channel-wise vector. KDA still keeps a single scalar βt for the active edit. That scalar controls two different things at once. It decides how much old content to erase on the key side. It also decides how much new content to commit on the value side. These two decisions act on different axes of the state. Tying them together is a modeling restriction, not a property of the delta rule.