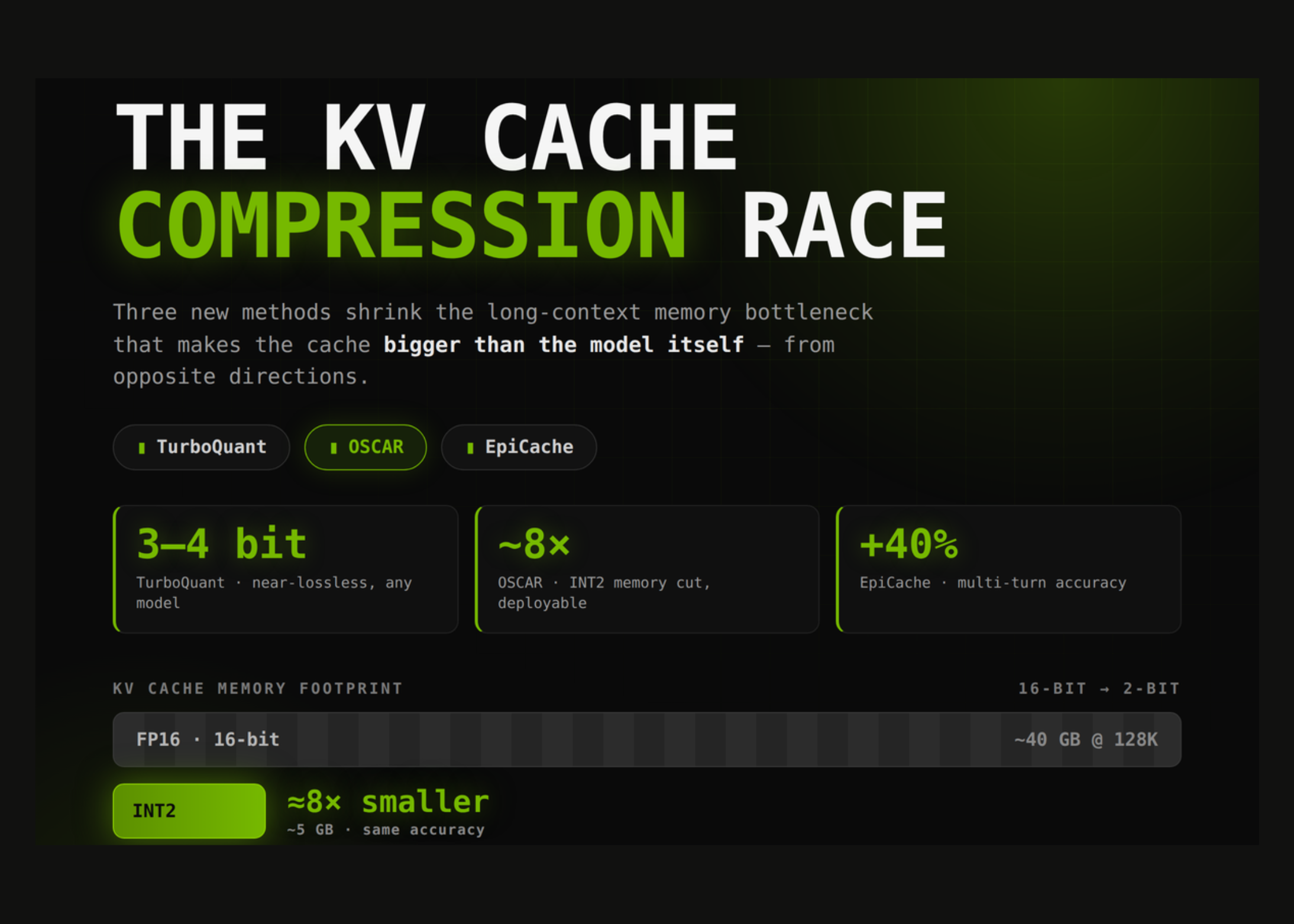
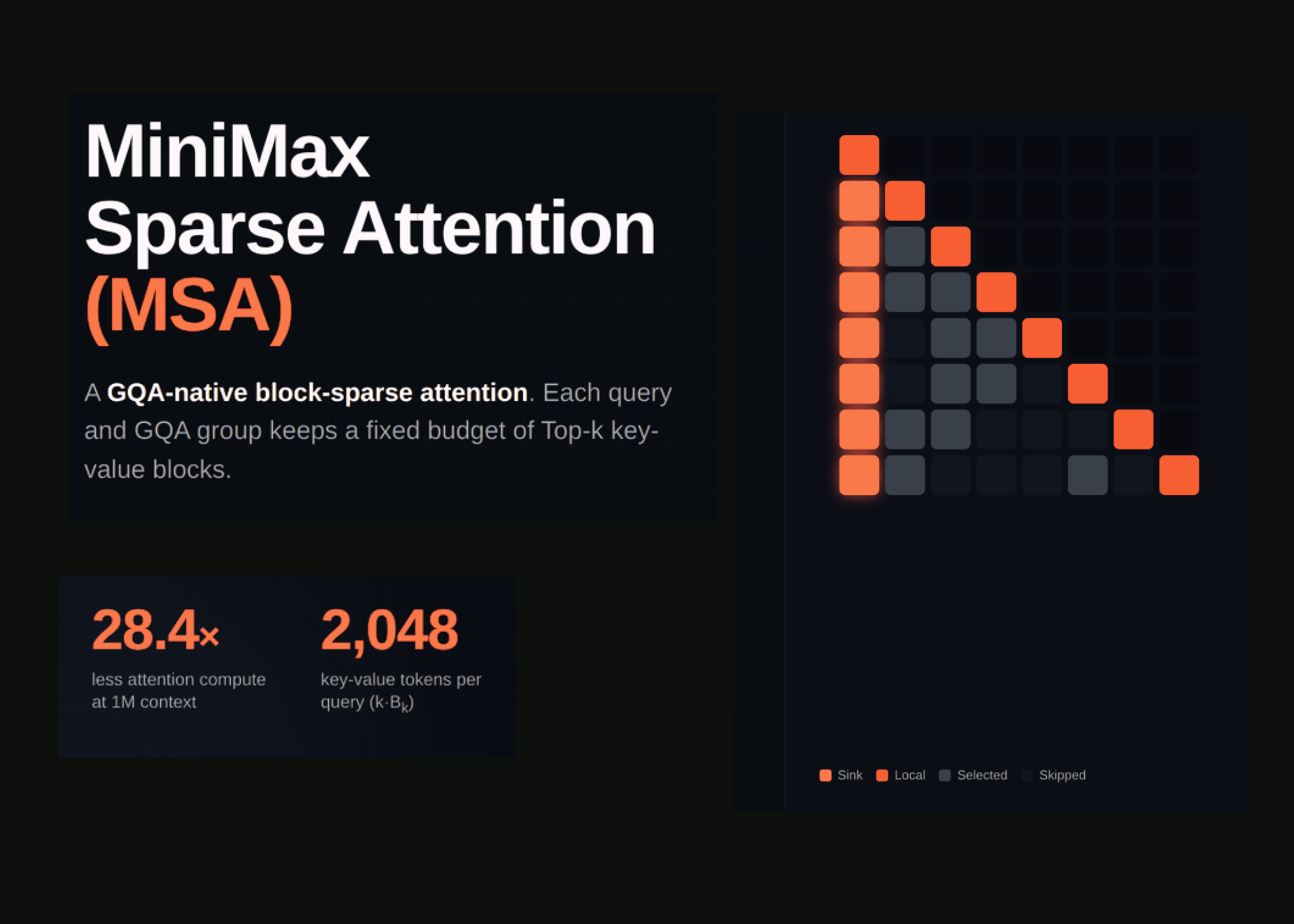
Sparse key‑value caches collapse the quadratic blow‑up of softmax attention into a cost that grows near‑linearly with sequence length. By making each query attend to a tiny, top‑k subset of blockwise KV memories, the per‑query work stops scaling with the full context. This tiny change flips the scalability curve for ultra‑long sequences and makes multi‑hundred‑kilobyte windows practical on a single GPU.
Before this work, the dominant recipe was dense attention, whose (O(N^{2})) memory and FLOP budget caps context windows at a few k tokens. Grouped Query Attention (GQA) improved cache reuse but still required each group to scan all KV blocks, leaving the quadratic term intact. Those approaches could not keep compute constant as the window grew, forcing a trade‑off between length and latency.
MSA cuts per‑token attention compute by 28.4× at a one‑million‑token context. The authors report, “On a 109B‑parameter model with native multimodal training, MSA performs on par with GQA while reducing per‑token attention compute by 28.4× at 1M context” [1]. The reduction deepens with length, as “As shown in Figure 4, MSA reduces per‑token attention FLOPs substantially relative to GQA in our setting, with the reduction increasing at longer contexts” [1].