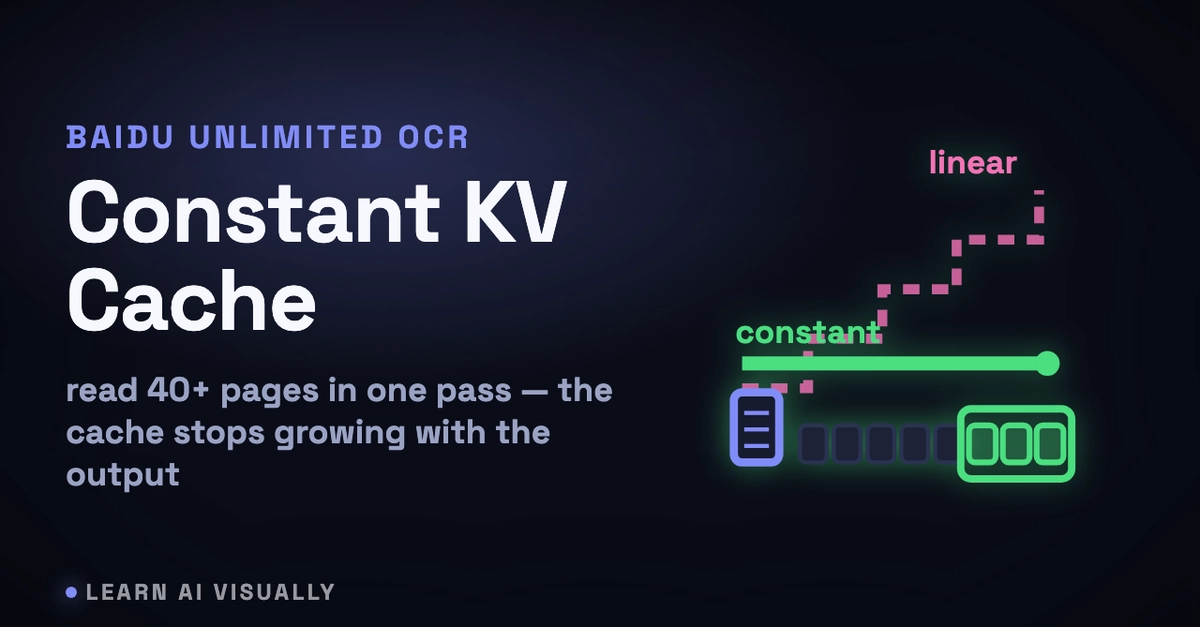
Most end-to-end OCR models slow down as output grows. Each generated token adds to the KV cache. Memory rises and generation drags. Parsing dozens of pages becomes impractical. Baidu’s Unlimited OCR addresses this directly. It swaps the decoder’s attention for a design that keeps memory constant.
TL;DR
Unlimited OCR is a 3B-parameter Mixture-of-Experts model, with only 500M parameters active.
It replaces decoder attention with Reference Sliding Window Attention (R-SWA), keeping the KV cache constant.
The model parses dozens of pages in one forward pass under a 32K maximum length.