Two themes dominated AI tooling this week: document parsing finally getting serious about production scale, and agent orchestration tooling maturing past the demo stage. Neither is hype—there are real implementation decisions here with concrete tradeoffs.
Unlimited-OCR parses multi-page documents end-to-end
Unlimited-OCR is a vision transformer that processes arbitrarily long documents in a single pass, supporting up to 32,768 tokens via a streaming API or batched inference. It handles both single-image and multi-page inputs without requiring you to chunk documents manually or write glue code to stitch results back together. Backend options are Transformers (simpler, single-doc) or SGLang (concurrent batch processing).
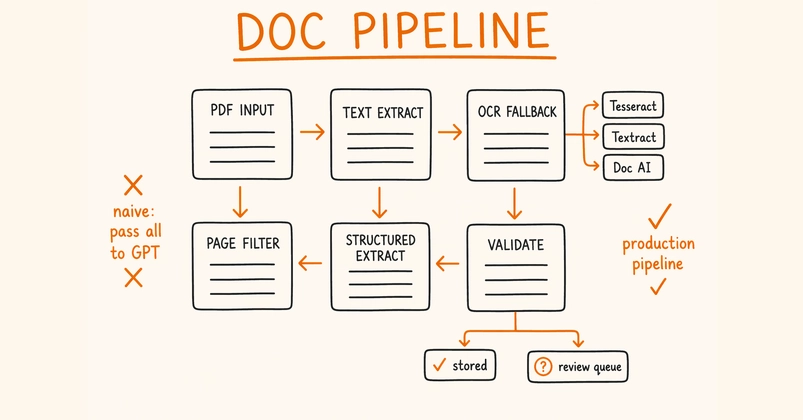
The elimination of the page-by-page loop is the real value. If you've built a PDF pipeline before, you know the loop: split pages, run OCR per page, normalize outputs, reconcile layout across page boundaries, hope nothing falls in a gutter. That's gone. The tradeoff is a hard dependency on CUDA 12.9+, torch 2.10.0, and transformers 4.57.1—these are recent enough that you'll need to audit your environment before dropping this in.
Verdict: Ship if you're on a greenfield pipeline and can meet the dependency floor. Pick SGLang for anything with concurrent load. Use the Transformers API if you're processing documents one at a time and want simpler ops.