Someone emails you a PDF invoice. You want to extract the vendor name, line items, total amount, currency, and due date — automatically, at scale, without manual keying.
You call the OpenAI API, pass the PDF as base64, get a JSON blob back. It works. You ship it. Then reality arrives: a scanned invoice from a vendor who still uses a physical stamp. A 60-page contract where the key clause is on page 47. A table-heavy bank statement where amounts bleed across column boundaries. A PDF that's actually an image with no embedded text at all.
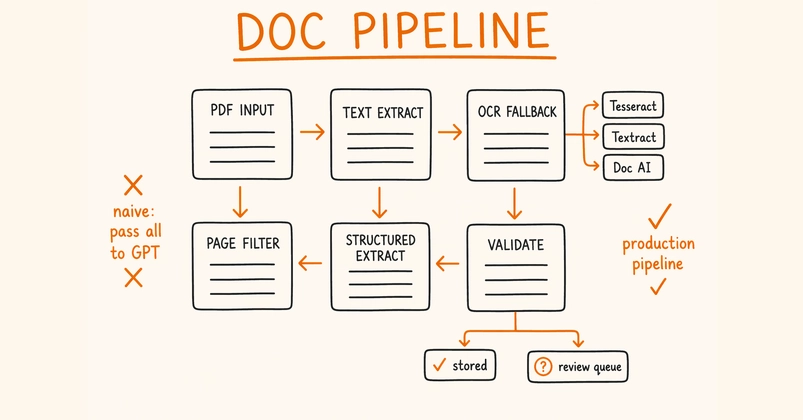
The naive approach collapses on all of them. Here's the production architecture that does.
Why the Naive Approach Breaks
The simplest version — encode the whole PDF, send it to GPT, ask it to return JSON — fails in four common ways: