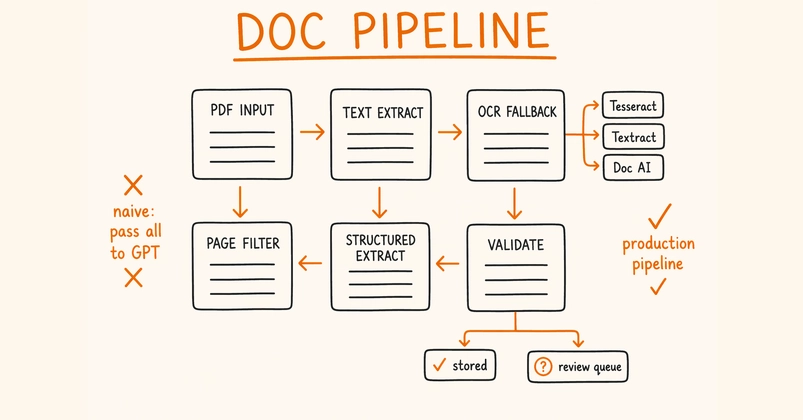
The Hard Part Is Not Calling the Model
Most document automation projects fail before the first extraction prompt runs.
The invoice is a scanned PDF. The contract is a DOCX with images pasted into the appendix. The email has a PDF attachment and an inline HTML body. The spreadsheet has four tabs, merged headers, and values formatted as currency. The website looks fine in a browser but ships half of its content through JavaScript.
If your pipeline assumes "file in, text out," all of that becomes glue code. You add a PDF parser. Then OCR. Then an HTML cleaner. Then a spreadsheet reader. Then a special case for images. Then a special case for emails. Then a retry path because one vendor returns empty text for scanned documents and another returns malformed table output.
The LLM is usually not the bottleneck. The bottleneck is getting the source material into a representation the LLM can read reliably, which is why document parsing quality matters before extraction prompts, RAG chunking, or agent workflows begin.