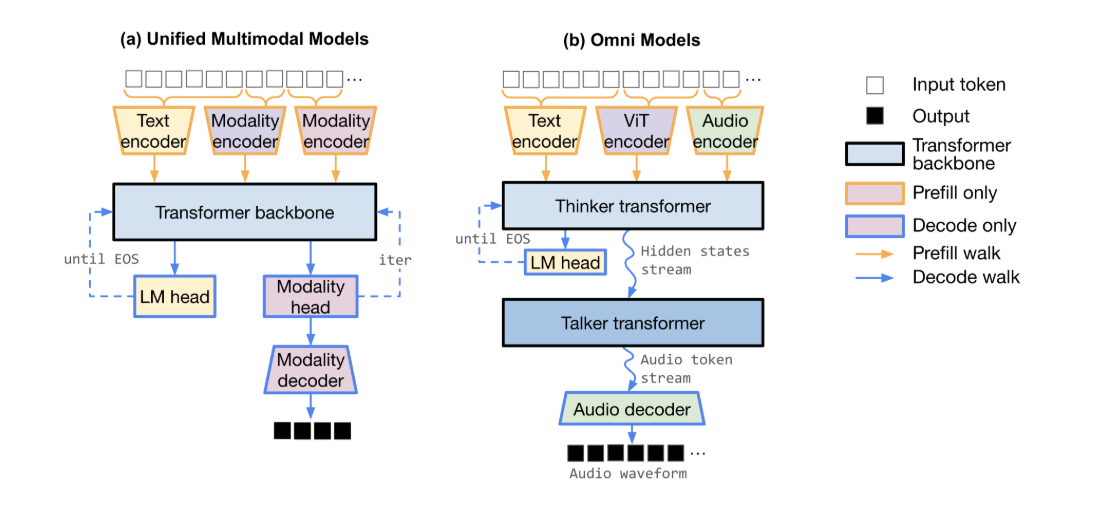
MiniMax released MSA (MiniMax Sparse Attention), a sparse attention method built directly on Grouped Query Attention (GQA). It targets one bottleneck: the quadratic cost of softmax attention at long context. The MiniMax research team tested it inside a 109B-parameter Mixture-of-Experts model trained with native multimodal data. They also open-sourced an inference kernel and shipped a production model, MiniMax-M3.
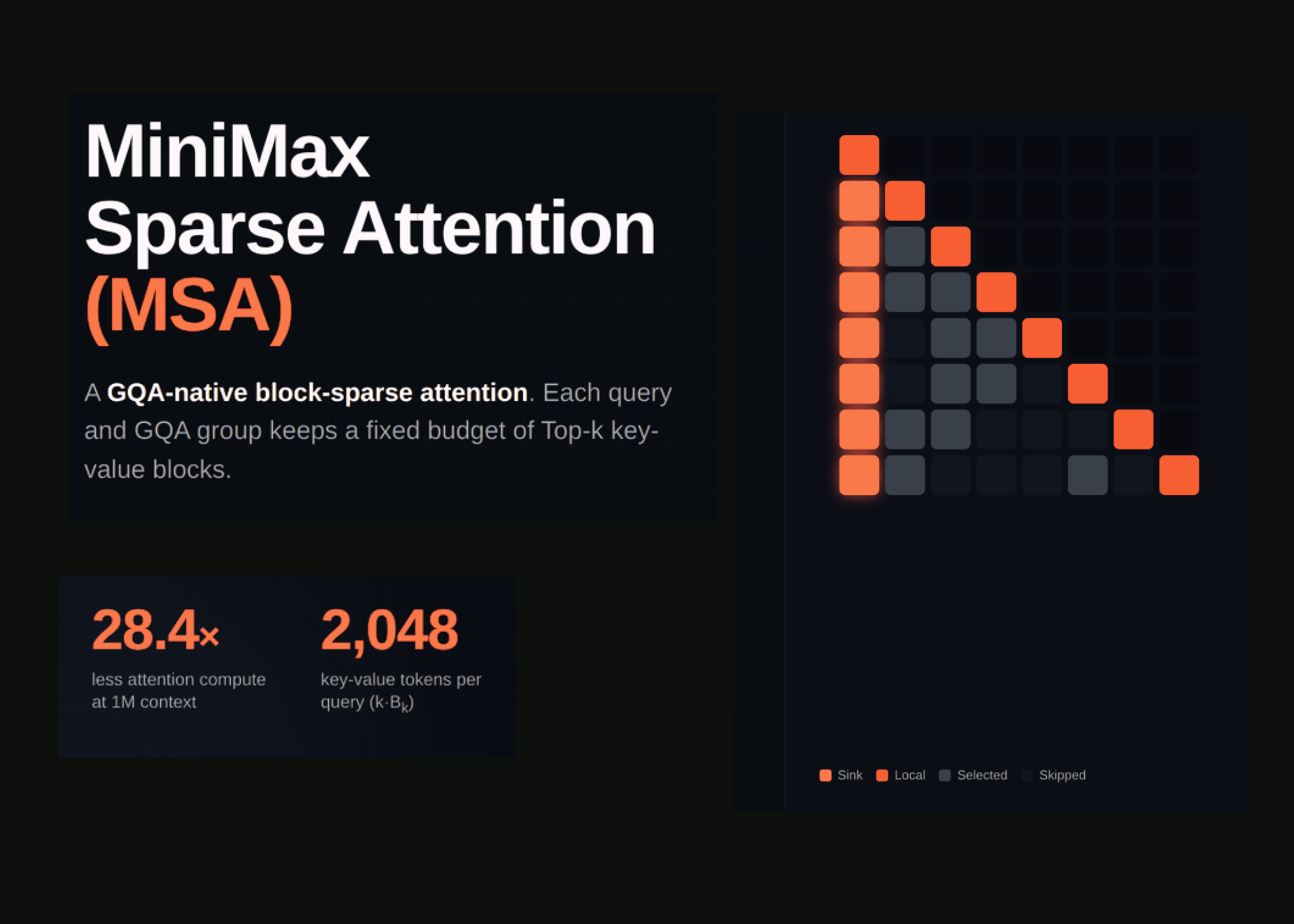
MSA (MiniMax Sparse Attention) factors attention into two stages: an Index Branch and a Main Branch. The Index Branch decides which key-value blocks each query should read. The Main Branch then runs exact softmax attention over only those blocks.
Selection happens at block granularity, not per token. The default block size is Bk = 128 tokens. Each query and GQA group keeps k = 16 blocks. That fixes the per-query budget at kBk = 2,048 key-value tokens.
The two cost structures differ. Dense GQA attention scales per query as O(N), the full context. MSA scales as O(kBk), which stays fixed as N grows. The compute gap therefore widens as context length increases.
Selection is shared inside each GQA group but independent across groups. One key-value head serves several query heads, and they share one block set. Different groups can attend to different long-range regions.