Home
Storia in 1 fonti
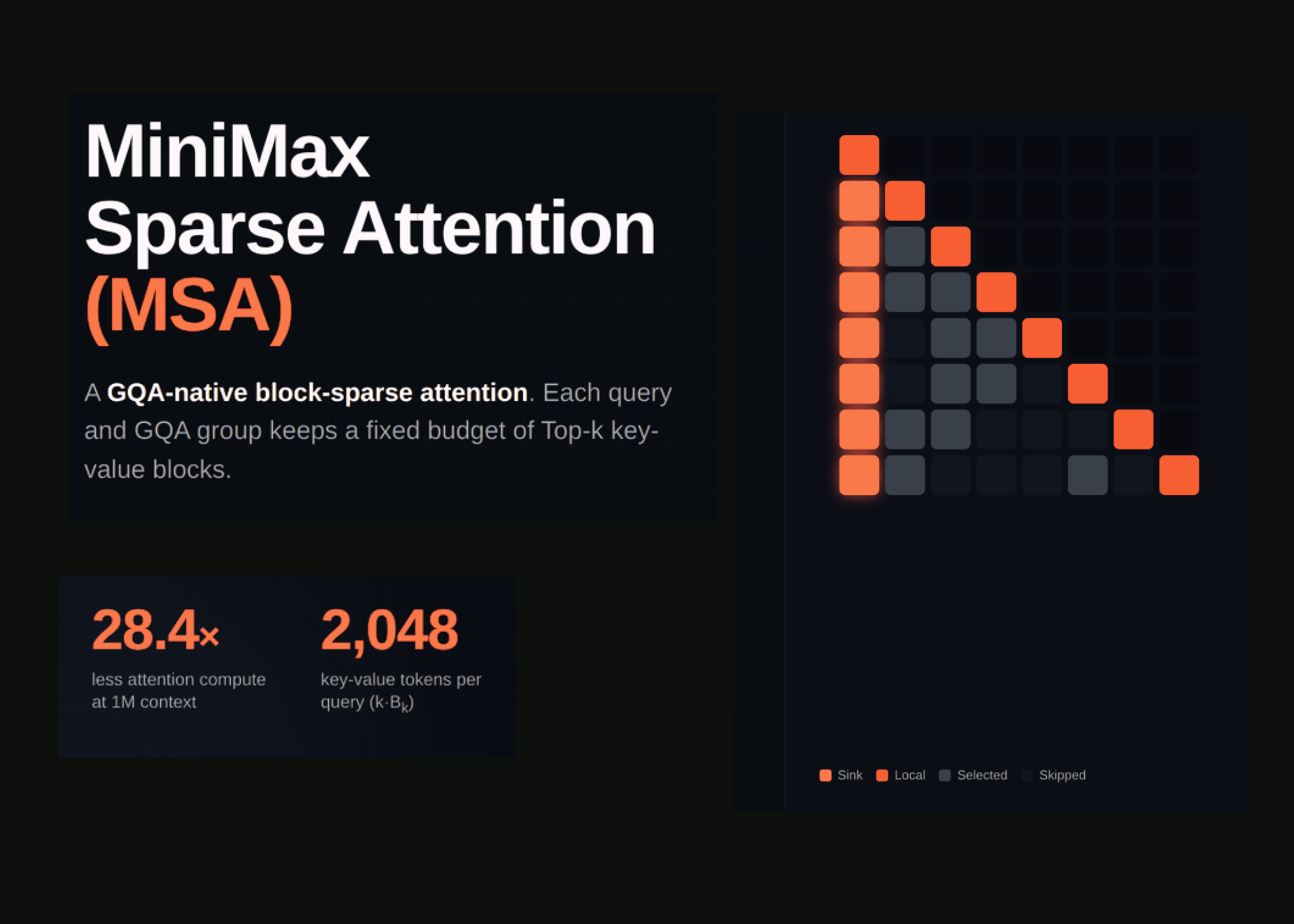
MiniMax Sparse Attention (MSA): a Two-Branch Block-Sparse Attention Trained on a 109B-Parameter MoE With a 3T-Token Budget
MiniMax Sparse Attention (MSA) is a GQA-native block-sparse attention that cuts per-token attention compute 28.4× at 1M context
Raccontata da marktechpost.com
marktechpost.com