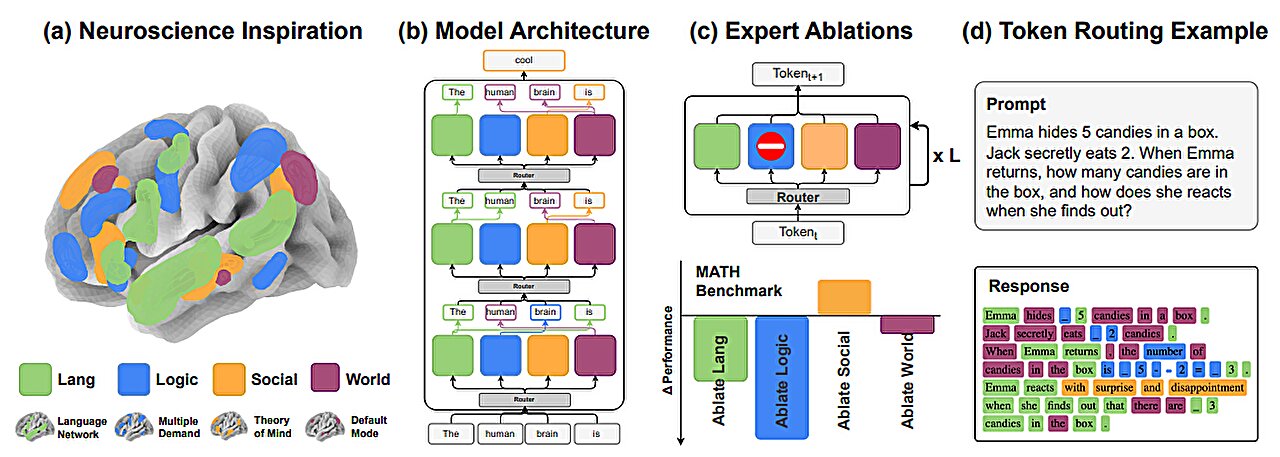
Notes following a discussion on how memory works in language models - and how it could be improved: ranging from the common issue of "context window" exhaustion to node architecture and entity linking.
1. The illusion of an infinity chat.
No model possesses a truly infinite context; the window size is always finite. The illusion of a continuous dialogue is maintained through information compression and selection mechanisms. Specific approaches include: Infini-attention (from Google) - a compressed long-term memory mechanism built on top of standard attention; it reportedly maintains performance quality even when exceeding the million-token threshold. StreamingLLM - utilizing several "anchor" tokens at the start of the sequence combined with a sliding window for recent tokens. MemGPT/Letta - a system resembling OS virtual memory that incorporates three tiers: core memory (always within the context window), archival memory (in vector storage), and recall memory (the full history in a database). Mem0 - instead of summarizing everything indiscriminately, it selectively stores only significant facts, reducing token volume by 80–90%. Also worth mentioning is EM-LLM: this model segments history not mechanically, but based on a "surprise" metric - an approach that appears to mirror the workings of human memory.