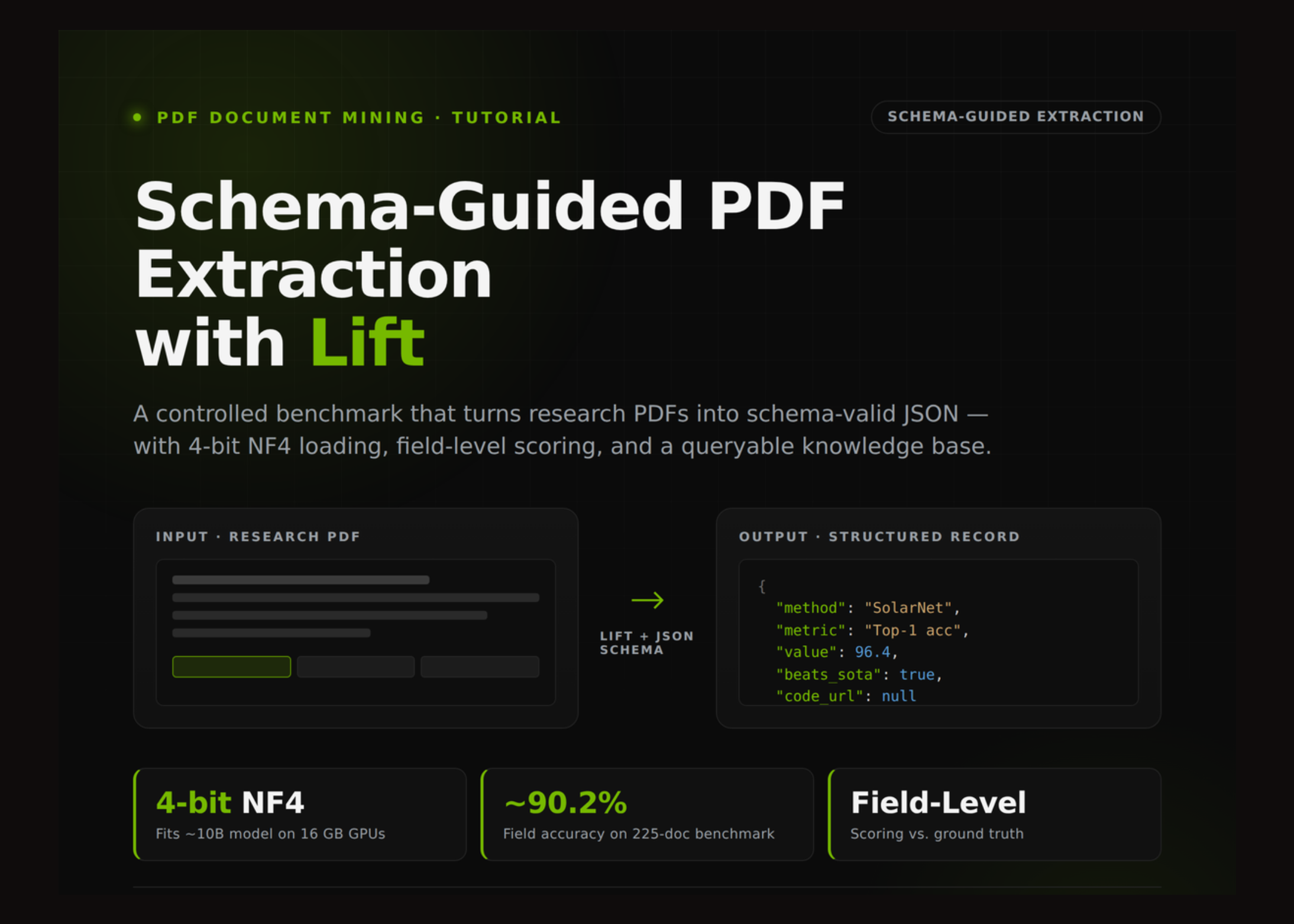
In this tutorial, we build a complete PDF-to-structured-data extraction workflow around Lift, with a focus on controlled evaluation rather than a simple demo run. We begin by preparing a Colab-compatible GPU environment, selecting the appropriate precision mode for the available hardware, and patching model loading to ensure the Lift backend runs reliably even on constrained 16 GB GPUs via 4-bit NF4 quantization. From there, we generate synthetic multi-page research reports with deliberately placed distractors, including validation-versus-test metric ambiguity, baseline-versus-proposed-model comparisons, missing code-release cases, and boolean state-of-the-art claims. This provides a realistic testbed for schema-guided extraction, in which the model must recover titles, authors, datasets, metrics, hyperparameters, limitations, and repository links from document layouts rather than plain text.
Configuring Runtime and Dependencies
N_DOCS = 3
FORCE_FULL_PRECISION = False
FORCE_4BIT = False