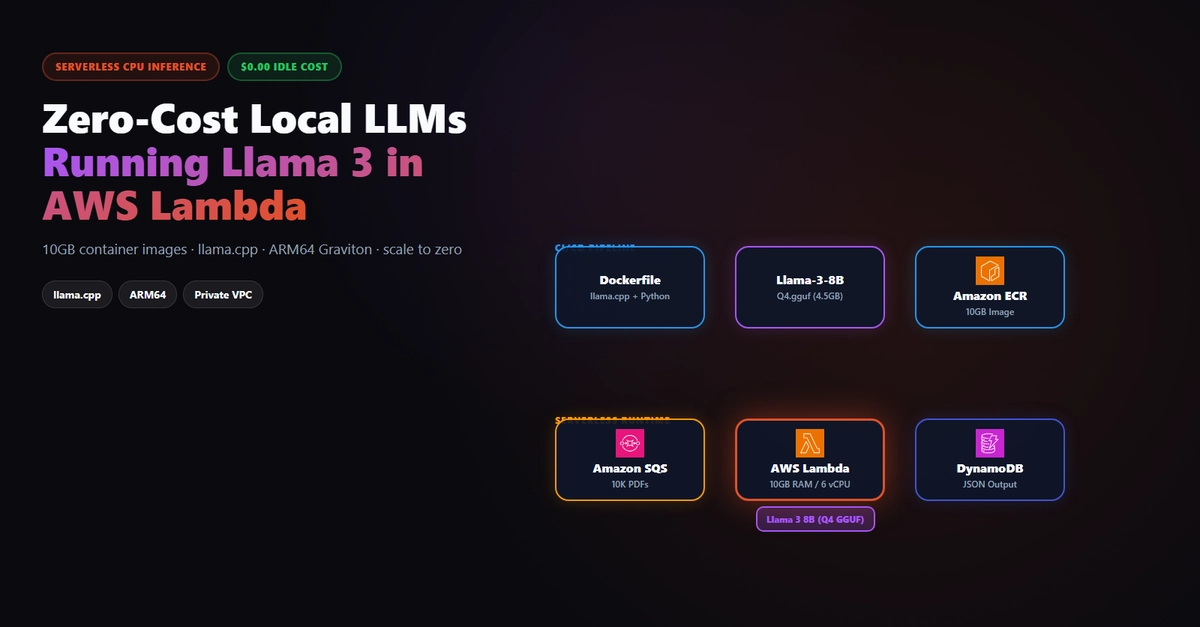
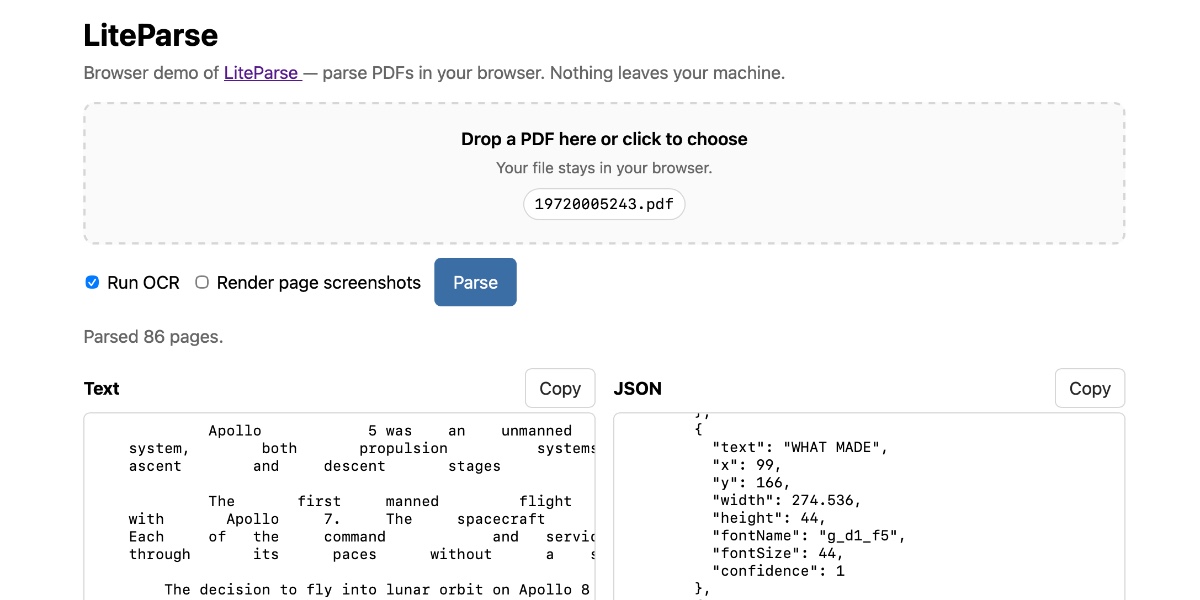
1.🚀 Introduction
Processing scientific PDFs is not as simple as extracting text.
Many papers include tables, multiple columns, formulas, figures, and structures that can easily break when we use traditional extractors.
The problem becomes even bigger when those documents are private. We do not always want to depend completely on multimodal models to analyze them, and the cost can also grow quickly when we work with many files.
A few months ago, I attended PyData Berlin and during one of the talks I discovered IBM Docling, an open source project focused on intelligent document processing. What caught my attention the most was its ability to extract structured information from complex PDFs, especially scientific documents with tables, multiple columns, formulas, and layouts that are difficult to process with traditional tools.