23rd April 2026
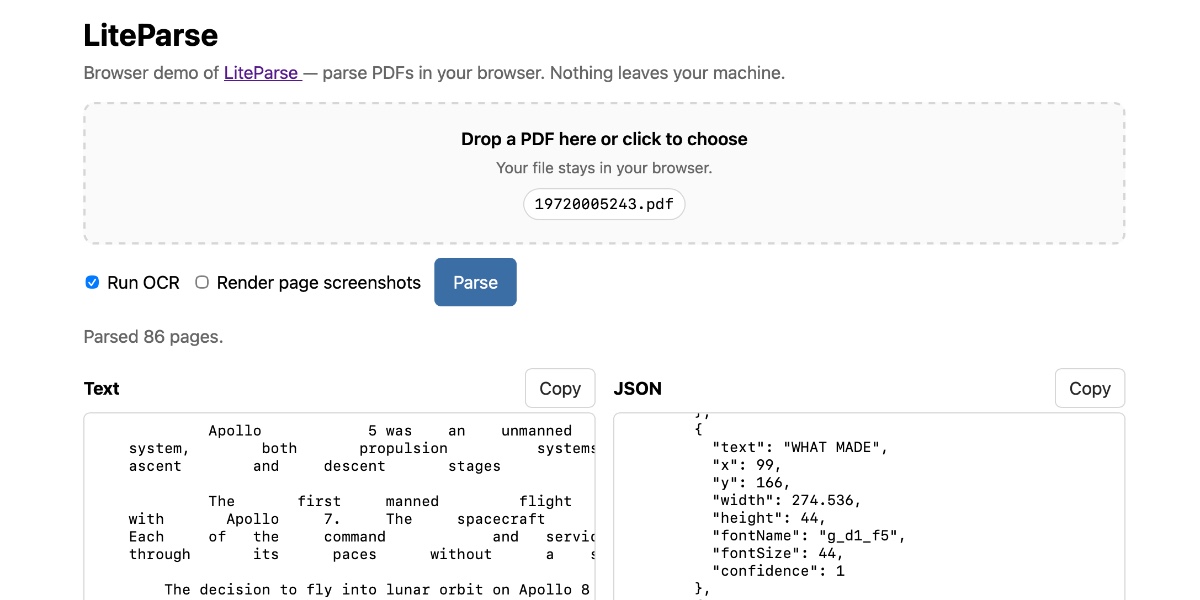
LlamaIndex have a most excellent open source project called LiteParse, which provides a Node.js CLI tool for extracting text from PDFs. I got a version of LiteParse working entirely in the browser, using most of the same libraries that LiteParse uses to run in Node.js.
Spatial text parsing
Refreshingly, LiteParse doesn’t use AI models to do what it does: it’s good old-fashioned PDF parsing, falling back to Tesseract OCR (or other pluggable OCR engines) for PDFs that contain images of text rather than the text itself.
The hard problem that LiteParse solves is extracting text in a sensible order despite the infuriating vagaries of PDF layouts. They describe this as “spatial text parsing”—they use some very clever heuristics to detect things like multi-column layouts and group and return the text in a sensible linear flow.