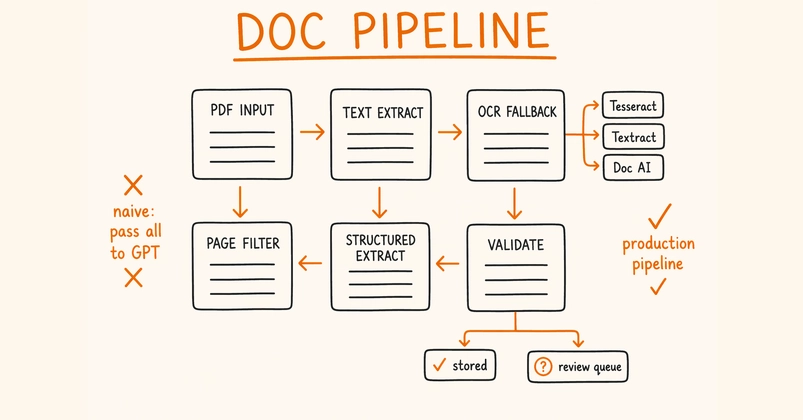
Picture this: a compliance officer needs a specific clause during an audit, an attorney needs contract terms while a client waits on the phone, or a finance analyst needs numbers from last quarter’s report before a meeting that starts in 10 minutes. In each case, waiting for a scheduled job to finish is not practical. You need on-demand access to the text inside your PDFs.
In this post, you’ll build a server that extracts text from PDF files in Amazon S3 in real time. This protocol-based approach provides programmatic document access. You’ll walk through the architecture, set up the server, and run interactive document queries. Along the way, you’ll compare this approach with Amazon Textract so you can decide which tool fits your workload.
We built this solution after working with several teams who shared the same frustration: their documents lived in Amazon S3, but getting text out of them on demand meant either writing custom scripts or waiting on batch pipelines. This MCP server approach sits in between, giving you interactive access with minimal setup. Interactive PDF text extraction from Amazon S3 gives you real-time answers from your documents without batch pipelines or heavy infrastructure.